
Qu’est-ce qu’un "contenu de qualité" pour Google ? Pourquoi et comment l’évaluer ?
La qualité des contenus, c'est le leitmotiv de Google : c’est LA chose à travailler pour optimiser le positionnement d’un site dans ses résultats, dit le moteur de recherche. Mais qu’évaluer ? Quel impact sur le référencement ?
Qu'est-ce qu'un contenu de qualité ? Sur quels éléments concrets les robots des moteurs de recherche peuvent-ils s’appuyer ? Comment un moteur de recherche peut-il mesurer la qualité de contenus pour traduire des perceptions utilisateur ? Et en amont, décider d’explorer certaines pages ou pas ? Quels critères spécifiques évaluer pour s'assurer que son site répond aux attentes qualitatives ? Où sont les éventuels leviers d’optimisation ?
Qualité perçue par un humain et par un robot
Le contenu que nous produisons est destiné à une audience humaine. Mais c’est la façon dont les moteurs de recherche traduisent la perception humaine, et intègrent la notion de qualité à leur fonctionnement pour la constitution de leur index, qui va déterminer la performance d’un site dans leurs pages de résultats. La notion de qualité impacte donc le comportement des moteurs de recherche à plusieurs niveaux.
Les moteurs de recherche détectent d’abord de manière directe la qualité perçue par les internautes, au travers de l’analyse de leur comportement. Par exemple, si les internautes ont trouvé la page dans les résultats de recherche, cliquent sur le lien mais ne restent pas sur la page, Google le saura. Il pourra mesurer le taux de rebond, en déduire que le contenu est peu intéressant ou répond mal à la requête, et tenir compte de ce feedback humain pour modifier ses résultats.
Avant d'apparaître dans une page de résultats, une page doit avoir été explorée et indexée par le moteur de recherche. Or, la qualité perçue par les robots va impacter le fait qu'une page sera explorée ou non. Si des pages, voire des sections entières d'un site, sont de faible qualité, les moteurs de recherche peuvent décider de leur affecter une priorité très basse dans leur algorithme d’exploration, en leur attribuant peu ou pas de budget de crawl. Si la page n'est pas crawlée, elle ne pourra pas être indexée. Elle ne pourra en aucun cas apparaître dans les résultats, quand les internautes posent une question à laquelle la page pourrait peut-être répondre.
Puisque la qualité du contenu des pages a un impact aussi fort sur le trafic organique du site, il est indispensable d'analyser la qualité du contenu d'un site comme le ferait un moteur de recherche. La question devient : sur quels éléments, que nous pouvons aussi mesurer, un moteur de recherche peut-il se baser pour évaluer la qualité d'un contenu ?
Comment décortiquer la qualité en éléments mesurables ?
On le sait, l’essentiel repose sur deux critères : la taille du contenu des pages (il faut que l’internaute ou le moteur de recherche ait quelque chose à se mettre sous la dent), et le taux de duplication du contenu (est-ce qu’une page apporte de nouvelles informations, par rapport aux autres). Tout responsable SEO fait la chasse au thin content et aux duplicatas. L’important, c’est la pertinence de ce que l’on mesure pour évaluer ces critères. Pour la taille du contenu, facile, il suffit de compter le nombre de mots.
Au niveau des duplicatas, les choses se corsent un peu. Les duplicatas complets, c’est-à-dire les pages vraiment quasi-identiques, ne sont que la partie émergée de l’iceberg. Elles sont généralement facilement détectables, par exemple via des balises Titre, H1, ou Meta-description en commun. On les a souvent déjà identifiées et traitées avec des balises canoniques, qui indiquent aux moteurs de recherche quelle est la version principale du contenu dont la page est une variante.
Ce qu’il faut pouvoir identifier également, c’est un phénomène plus insidieux, celui des pages qui disent seulement en partie la même chose. Les pages avec recouvrements partiels sont souvent bien plus nombreuses que les duplicatas complets. Les moteurs de recherche sont redoutablement efficaces à ce niveau, car c’est au cœur de leur fonction, qui est d’indexer des informations, donc de savoir lesquelles sont nouvelles ou pas. Il doit optimiser ses ressources d’exploration et mettre toutes les chances de son côté pour découvrir de nouvelles informations, par opposition à ce qu'il a déjà en stock.
Arrêtons-nous un instant sur la notion d’information. Une information, c’est finalement une suite de mots : un mot seul véhicule un sens limité, et qui peut changer selon le contexte ; il a tout de suite davantage de sens dans le contexte des quelques mots qui l’entourent, lorsque l’on considère des expressions. Pour évaluer le taux de duplication du contenu d’une page au sein d’un site, on peut donc évaluer la proportion de petites suites de mots que l’on retrouve dans d’autres pages – et dans combien d’autres pages.
Il ne s’agit pas de chercher à comprendre le sens des informations, on ne touche pas à l'analyse sémantique. On va pourtant refléter efficacement la perception de l’utilisateur, qui va se dire, en passant d’une page à l’autre, "ça dit grosso modo la même chose", même si le contenu n’est pas complètement identique. C’est purement du chiffrage de duplication d’information. L’étude sémantique des contenus est un autre axe d'analyse, que l’on n’aborde pas ci, et qui fournit un éclairage complémentaire, avec par exemple la proximité thématique entre les pages reliées par des liens, à laquelle l’utilisateur sera sensible ("ça n’a rien à voir avec ce que je regardais avant") et que les moteurs analysent également.
On veut donc évaluer la taille et le taux de duplication du contenu des pages. Mais ce n’est pas encore assez pertinent. Avant d’extraire ces indicateurs clé, il faut passer l’ensemble du contenu de la page au tamis: quand on regarde une page, seulement une partie de ce qui est à l’écran correspond à ce que cette page-là raconte. Le reste est de l’habillage.
Pre-requis absolu : où est le "vrai" contenu, par opposition à celui du template ?
Les moteurs de recherche sont capables d'identifier le "vrai" contenu d’une page. C'est à dire qu’ils savent séparer la partie spécifique à la page de la partie correspondant au template, soit les éléments de navigation et les informations connexes communes à d’autres pages (entête et bas de page, menu et barre de navigation, widget des dernières infos ou produits populaires de la section, etc.).
Faire cette distinction est un prérequis à toute analyse de contenu digne de ce nom, car Google va indexer la page et la présenter dans ses résultats sur la base de ce qui est au cœur de la page : ce qu'un utilisateur va percevoir comme le contenu en arrivant sur la page, ce qu’il vient y chercher.

[Légende: Le “vrai” contenu est en
vert, le template en rouge]
Si l’on évalue l'intégralité du contenu de la page sans séparer le "vrai" contenu du template, ou si la séparation est en décalage avec la perception humaine, alors les indicateurs de taille et d’unicité du contenu ne seront pas pertinents: on pourra penser qu'une page a un contenu de taille significative, alors que pour un utilisateur, elle est quasi vide; ou bien qu’une page comporte beaucoup de contenu dupliqué, quand il s’agit d’éléments de template auxquels l’utilisateur ne va pas prêter attention.
Le poids du template dans les pages n’est pas généralement pas, en soi, un élément à optimiser. C’est plutôt un état de fait, dicté par des besoins métier. Si l’analyse du template est importante, c’est avant tout pour pouvoir l’éliminer et évaluer uniquement le "vrai" contenu, ce sur quoi se focalisent les points suivants.
Tous les sites ne sont pas logés à la même enseigne
Une fois que l’on a obtenu la taille et le taux d’unicité de du vrai contenu des pages du site, quelles conclusions tirer ?
Les moteurs de recherche n'ont pas les mêmes attentes pour tous les types de sites, ni pour tous les types de pages. Parce que les utilisateurs non plus. Il est normal que le contenu type d’une page web varie grandement par secteur d'activité, par sujet, et surtout, par objectif de la page, qui correspond à l'intention de l’utilisateur : s'informer, acheter, … Par exemple, une page produit peut comporter peu de contenu, si le site marchand possède peu d'informations sur le produit. Pour l’utilisateur, c’est acceptable. C'est encore plus flagrant pour un site de petites annonces, typiquement très courtes, voire de style télégraphique. A l'opposé, on s’attend à ce qu’un site de type éditorial comporte essentiellement des pages riches, et au contenu majoritairement original (au sens "unique sur le site", ce qui sera par exemple moins le cas pour une page produit).
On ne peut donc pas définir de bonnes pratiques universelles, d’idéal en termes de taille ou d'unicité du contenu. Parce que Google sait pertinemment que les attentes de l’utilisateur varient selon le type de site et le type de requête, parce qu'il sait aussi bien sûr distinguer un site marchand d'un site d'informations. La notoriété du site peut aussi influencer les attentes de Google : si le site est très populaire, c’est un site de référence – les utilisateurs le choisissent majoritairement dans les résultats – Google sait que c’est là que les utilisateurs veulent aller, même si d’autres sites sont meilleurs en terme de qualité pure. Bref, la recette qui marche ne sera pas la même sur tous les sites.
Rien n’empêche de se fixer des objectifs assez bas : par exemple valider, pour les pages ayant vocation à générer du trafic organique, celles avec un minimum de 100 mots et pas plus de la moitié leur contenu retrouvé ailleurs. Mais se contenter du minimum syndical, sans prendre en compte les spécificités du site, serait passer à côté des vrais enseignements, et des opportunités d’optimisation. La clé pour bien exploiter ces informations se trouve dans la compréhension des attentes de Google pour notre site, spécifiquement.
"Trop peu" de contenu, c’est combien?
Pour comprendre où Google place la barre sur notre site, et ce, pour chaque type de page, il faut pouvoir croiser les indicateurs de qualité de contenu avec des indicateurs de performance SEO. Le plus facile sera certainement de regarder le volume de visites organiques : quelle est la taille des pages qui génèrent des visites, comparée à celle des pages qui n’en reçoivent aucune ?
Voici un exemple de site éditorial où plus les articles sont fournis, plus ils amènent de trafic :

[Légende: Une page active est une page qui a généré du trafic organique au cours des 30 derniers jours – peu importe le volume. La dimension affichée (barres) est le nombre de mots hors template des pages]
Et voici un site d’annonces où l’on observe un palier, à 200 mots, en dessous duquel les pages de listes d’annonces sont bien moins performantes :

[Légende: Une page active est une page qui a généré du trafic organique au cours des 30 derniers jours – peu importe le volume. La dimension affichée (barres) est le nombre de mots hors template des pages]
On peut aussi aller un peu plus loin que la simple question "La page génère-t-elle du trafic ou pas ?" et regarder le volume de visites par pages en fonction de la taille du contenu. Pour le premier exemple, celui du site éditorial, cela donne :
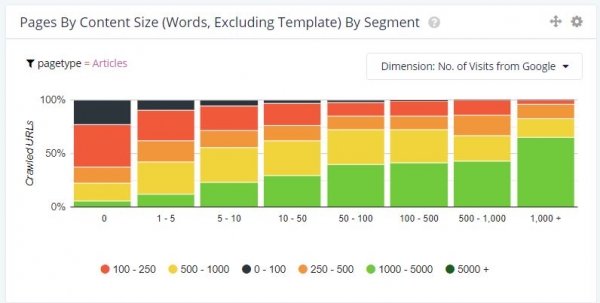
On constate qu’au-delà d’être plus nombreuses à générer du trafic, les pages avec une taille significative de contenu génèrent aussi davantage de visites chacune.
Si l’on possède des informations sur le crawl de Google (via de l’analyse de logs serveurs, qui permet de savoir quelles pages sont explorées par le moteur de recherche), alors on pourra aussi mapper les indicateurs de qualité de contenu au comportement d’exploration de Google : on connaîtra le "profil type" des pages crawlées vs celles ignorées. Si l’on a aussi des informations de positions et d’impressions dans les pages de résultats de Google (informations fournies par la Google Search Console), on aura encore plus de visibilité sur la raison qui fait qu’une page ne génère pas de trafic : même pas explorée, explorée mais jamais présentée dans des résultats ; présentée dans des résultats mais jamais cliquée.
Quelle part de contenu dupliqué est tolérée par Google ?
Comme pour la taille du contenu, on peut observer la corrélation entre le taux de duplication des pages et les indicateurs de performance SEO. Le graphique ci-dessous montre que sur le site d’annonces, les pages de listes ne génèrent de trafic organique que lorsqu’il n’existe pas plus de 2 pages similaires.

[Une page active est une page qui a généré du trafic organique au cours des 30 derniers jours – peu importe le volume. La dimension affichée (barres) est la taille, en nombre de pages, des groupes de pages avec fort recouvrement, c’est-à-dire ayant au moins 75% de leur contenu hors template en commun.]
Conseil pratique : exclure les pages quasi vides avant de mesurer les recouvrements de contenus : s’il y a très peu de contenu, le pourcentage en commun sera potentiellement très vite haut, ce qui risque de masquer les vrais enseignements. Et de toute façon, Google aura probablement déjà négligé ces pages sur le critère de la taille du contenu.
Des pages de faible qualité viennent-elles "polluer" une zone stratégique du site ?
Puisque Google se sert de critères de qualité de contenu pour décider où sont les zones du site à explorer de manière prioritaire, on doit aussi se demander si des pages de faible qualité ne viennent pas nuire à celles à fort potentiel.
Si une section du site comporte des pages stratégiques de grande qualité, mais est polluée par une quantité significative de pages de basse qualité, au global, la zone ne sera que moyennement satisfaisante. Les moteurs de recherche, qui doivent décider que crawler, à l’échelle d’un site, peuvent affecter une priorité moyenne à l’ensemble. Résultat, la zone sera moins explorée que si elle ne comptait que les pages de qualité, et Google pourrait passer à côté de pages à fort potentiel de trafic. Si l’on élimine les pages de basse qualité, la zone devient immédiatement plus attractive.
A noter qu’éliminer ces pages ne veut pas forcément dire les supprimer du site. Tout dépend si elles sont utiles à l’utilisateur qui navigue sur le site ou pas. Si elles le sont, il s’agit juste de faire en sorte que les moteurs de recherche ne les explorent pas (en les interdisant ou en rendant les liens qui pointent vers elles non crawlables).
En concentrant la qualité de la zone, les bénéfices sont multiples : Google ne gaspillera plus de budget de crawl sur des pages qui ne le méritent pas ; il sera enclin à explorer davantage la zone ; et puisqu’on lui fournira du contenu plus concentré (plus de contenu unique par page ou plus de contenu tout court), le moteur de recherche va récupérer davantage d’informations, via le même budget de crawl. Le site aura immédiatement un plus grand nombre de cartes à jouer dans les résultats de recherche : il sera susceptible de se positionner sur une plus grande variété de requêtes.
Est-ce que le contenu a changé ?
Un aspect souvent négligé de l'analyse de contenu est celui de l'analyse des changements. Imaginons que des pages qui génèrent une partie significative du trafic organique sur le site, voient leur contenu changer du tout au tout du jour au lendemain. Si ce que les internautes venaient y chercher n'y est plus, le trafic organique peut chuter brutalement.
C'est pourquoi une bonne analyse de contenu détecte aussi les changements très tôt, idéalement avant qu’ils produisent des dégâts. D’autant que certains changements dans les pages peuvent facilement passer inaperçu lors d’analyses SEO plus basiques, en particulier lorsque la taille du contenu, les tags HTML destinés aux robots (H1, title, meta-description) et les liens menant à la page n'ont pas changé.
C’est exactement la même approche que lorsque l’on détecte des recouvrements de contenus entre deux pages : on compare simplement deux versions d’une même page au fil du temps.
Attention aux fausses alertes cependant, on ne veut pointer du doigt que ce qui est anormal : si l’on s’attend à ce qu'une une page de catégorie qui liste des produits voie une partie de son contenu changer quand le catalogue évolue, on ne s'attend a priori pas à ce que le contenu d'une page produit change entièrement. On en revient à la nécessité de mener toutes ces analyses par type de page.
Que retenir
L'analyse de la qualité du contenu est un point essentiel du SEO. On ne peut pas opposer les critères de qualité perçus par les utilisateurs et ceux perçus par les robots des moteurs de recherche, puisque l’objectif des seconds est de correspondre aux premiers. Mais l’impact des critères de qualité détectés par les robots va au-delà, car ils ne dictent par uniquement les positionnements dans les pages de résultats, ils sont aussi intrinsèquement liés au fonctionnement des moteurs de recherche en tant que gestionnaires d’information.
Pour être pertinente, l’analyse de la qualité de contenu a besoin de deux choses :
- D’indicateurs de qualité de contenu pertinents que l’on peut mesurer via des outils spécialisés et qui reflète la façon dont les moteurs de recherche fonctionnent,
- D’une approche méthodologique rigoureuse qui décortique ces indicateurs de qualité par type de page (page de catégorie, produit), et les compare à des indicateurs de performances organique (trafic organique, exploration des moteurs de recherche) afin de tirer les conclusions spécifiques au site et ainsi identifier les leviers de croissance.