
Apache Camel (second volet) : transformation des données d'un fichier texte Transformation de données avec Camel : le cas des gros fichiers
A l'utilisation, le code précédent présente un défaut, qui n'apparaît que lors du traitement de "gros" fichiers. Dans ce cas, il est probable que l'on rencontre des erreurs de saturations mémoires. Par exemple, avec un fichier de 4 Mo environ, on obtient avec Java VisualVM le graphe mémoire suivant :

Lire le fichier en mode streaming
La consommation mémoire est beaucoup trop importante par rapport au traitement. C'est une conséquence de la façon dont le splitter fonctionne. Heureusement, il est possible de lire le fichier d'entrée par morceaux en mode "streaming". En ajoutant streaming() à la route :
from("file:/tmp/csv?noop=true&fileName=test.csv")
.split(body().tokenize("\n"))((/public/memoire_camel/memory-csv-nostream.png|Evolution mémoire sans streaming|C))
.streaming()
.log("ligne: ${body}")
.unmarshal().bindy(BindyType.Csv, "org.netapsys.csv.descripteur")
.bean(ImportBindy.class).end();
Le graphe montre une diminution très significative de la mémoire :
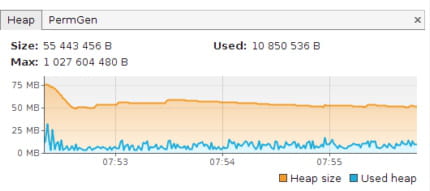
Conclusion : l'utilisation du streaming est toujours préférable dès que le volume des données à traiter est un peu important. De plus, en mode streaming, la charge CPU est moindre car le gestionnaire mémoire est moins sollicité.