
Serverless, REX d’une expérimentation avec AWS
Retour d'expérience sur la solution Lambda d'Amazon Web Services. Observations et convictions quant au serverless, cette technologie du futur !

Le serverless, mais qu’est-ce que c’est ?
Ce n’est pas un secret, la virtualisation et sa déclinaison dans le cloud ne se sont pas imposées à tort en entreprise. Flexibilité de mise en œuvre et d’exploitation, assurance d’une meilleure disponibilité ou encore opportunités en termes de scalabilité, les avantages sont là. Cependant, hormis le choix de services SaaS spécialisés et clé en main, l’utilisation des solutions cloud privées ou publiques nécessite une première estimation de dimensionnement (RAM, stockage, mémoire). Une gestion fine du capacity planning est aussi à prévoir. Cette dernière sera bien adaptée dans les cas de montées en charge progressives mais s’avère moins optimale face aux montées en charges brusques.
En réponse à ces problématiques, une solution émerge : le serverless. Ce concept fait le buzz depuis 2015 avec la solution Lambda de AWS, premier cloud public à proposer l’offre. Le serverless consiste comme son nom l’indique à faire tourner son applicatif sur une infrastructure sans serveur. Dans les faits, ce n’est bien évidemment pas le cas. Des serveurs, il y en a ! Leur exploitation ainsi que leur administration sont simplement transparentes car à la charge du fournisseur cloud. Enfin, le serverless avec une tarification à l’usage promet un lissage des coûts plus fin que le cloud du fait qu’on paye au temps d’exécution. Ce dernier point n’est pas forcément synonyme de gain financier car tout dépend de l’utilisation faite du service.
Choix d'un cas d’usage pertinent
Dans la continuité de sa logique de se positionner sur l’innovation, le M’Lab de Magellan Consulting et les équipes d’architectes, nous décidons de démarrer une expérimentation avec la solution de AWS. En plus de capitaliser sur un savoir-faire, des réflexions sont menées pour raccrocher la technologie aux usages. L’exercice tient dans la recherche d’un cas d’utilisation illustrant la bonne compréhension des enjeux métier. Outre le gain en termes d’exploitation, l'intérêt d'une bascule vers une technologie sans serveur doit se justifier dans son utilisation. Pour cela reste à bien appréhender les principes sous-jacents à cette solution. Enfin, l’objectif est aussi de comparer les apports du serverless par rapport à une solution cloud classique.
Le moteur majeur du choix d’un cas d’utilisation serverless est le plan d'utilisation du service : erratique et sujet à des pics de volumétrie peu prévisible. Quand une solution cloud nécessitera des ajustements en termes de sizing, le serverless absorbera la charge au travers de sa scalabilité transparente. Quand cette solution cloud proposera un pricing statique, souscrire au serverless, ce n’est rien débourser en l’absence d’exécution du service.
Le second moteur de choix tient dans la nature même du serverless : évènementiel. Lors d'une absence de sollicitation du service, il est observé un temps de warm up de la fonctionnalité dégradant ponctuellement les temps de réponse. La solution métier doit donc tenir compte de ce fait. Le serverless apparait donc comme un bon candidat pour l’exécution de traitements batch back-office. Les services front peuvent être éligibles s’il n’y a pas de contrainte de SLA forte.
Enfin le dernier moteur de décision se repose sur la volonté de décliner son architecture SI avec la composante micro-service propre au serverless. La liberté qu’il apporte en termes de développement spécifique doit être challengée dans un contexte où des solutions métier peuvent répondre aux mêmes attentes.
C’est le ticketing évènementiel qui a retenu notre attention. L’inscription a des évènements s’effectue toute l’année. On observe d’importants pics de volumétrie lors des ouvertures de ventes mettant alors l’infrastructure en péril. La génération d’un billet est un service front qui peut justifier un temps de réponse flexible. L’expérience utilisateur n’en sera pas dégradée. C’est donc une problématique typiquement serverless.
Expérimentation avec AWS
En termes d’offres sur le marché, on compte en premier lieu, Amazon Lambda, pionnier ayant ouvert le marché fin 2014. Microsoft propose une version stable de son service depuis fin 2016 avec Azure Functions. Google Cloud Functions quant à lui est encore en version beta. Incubé par Apache, OpenWhisk devient avec IBM une offre commerciale de serverless : IBM Bluemix. Pour la maturité qu’implique son antériorité sur le sujet et l’écosystème riche qu’il offre en termes d’intégration, c’est AWS Lambda qui est choisi.
L’expérimentation va se faire en deux phases. Une première avec des appels unitaires pour tester le fonctionnement effectif de la technologie. La seconde, un test de charge sera effectué pour observer la capacité d’absorption de la solution.
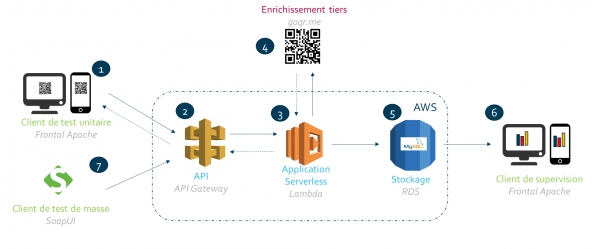
Depuis un frontal web (1), l’utilisateur s’enregistre avec ses données d’identité (nom et prénom) pour un évènement donné. L’API (2) collecte les informations de la requête pour déclenchement de la fonction Lambda (3). L’application se charge de solliciter la génération d’un QR Code à l’aide d’un service externe (4). Elle enregistre dans RDS (5), la base relationnelle d’Amazon, les informations de la transaction. L’utilisateur peut s’assurer du bon fonctionnement de la fonction serverless en décodant le QR Code qui contient les données de l’inscrit ainsi que le token de la transaction. La bonne intégration en base peut être observée par des graphiques de restitution (6) qui interrogent ladite base.
Le second cas d’usage interroge la capacité de scalabilité transparente qu’offre le serverless. A partir d’un client de test de masse (7), on émule un pic de charge sur l’utilisation du service. Le client de supervision (6), assurant une restitution visuelle sur l’utilisation du service, est le témoin de la bonne exécution de ce dernier.
Vidéo cas d’utilisation
Analyse des résultats
Sans surprise, Lambda répond aux attentes en ce qui concerne son fonctionnement nominal ainsi qu’en usage lors d’un pic de charge. Confirmant la théorie, il a été observé un délai de warm up lors d’une nouvelle exécution suite à une absence de sollicitation de la fonction.
On notera cependant qu’AWS atteint vite ses limites pour ce qui est du build ou du déploiement en proposant peu de fonctionnalités. Il est fortement recommandé de s’y interfacer avec Serverless Framework. Cette boîte à outils basée sur Node.js permet entre autre d’émuler localement une fonction. Il assure aussi un déploiement agnostique vers plusieurs infrastructures telles que celles d’Amazon, Microsoft et Google. Enfin, il faudra compter sur VS Code pour débuguer sa fonction à l’aide de points d’arrêt.
Pour ce qui est de l’architecture, l’intégration avec l’écosystème AWS a été facile à mettre en place du fait qu’on tire profit d’un environnement hautement intégré. Par exemple, l’intégration du serverless avec la brique d’API Management est du standard. A contrario, la difficulté à prendre en compte, le serverless, de par son identité micro-service a nécessité de penser unitaire. Il est donc important de s’interroger quant à la stratégie à avoir quant à la mise en place d’une telle solution dans un SI où le legacy compte son lot d’hétérogénéité.
Enfin, un autre résultat intéressant est celui du coût. D’après les simulations effectuées dans le cadre de notre expérimentation, nous constatons une adaptation avantageuse du coût global par rapport à une infrastructure cloud (EC2). On observe que le serverless tire profit du paiement à l’usage pour permettre une facturation inexistante (elle démarre à partir du million de requête par mois !) en temps de faible volumétrie. Le pic de volumétrie sera cependant facturé plus cher qu’avec la solution cloud. EC2, quant à lui, se contente de proposer une facturation fixe qui en cas de pic de volumétrie est plus avantageuse mais moins sur le long terme. Le serverless dans notre cas de figure se révèle près de trois fois moins cher que la solution cloud !
Cette expérimentation a été intéressante pour lever quelques considérations. Penser une architecture serverless nécessite un accompagnement pour étudier la forme qu’elle prendra et ainsi en tirer le meilleur profit. En effet, de mauvais choix pourraient annuler les gains attendus.
En premier lieu, il faut identifier les usages éligibles et ceux qui ne le sont pas. Ensuite du fait de sa singularité, micro-service et sans serveur, il doit être pensé la gouvernance (processus et outils) pour s’intégrer dans un SI qui ne serait pas encore mature à ces spécificités. Le choix du framework (AWS, Microsoft, etc.) prendra part à ses réflexions. Enfin, outre l’avantage en termes d’exploitation, si le coût est un levier d’adoption, une analyse fine des gains sera à mener.
En guise de conclusion, on pointera le fait que le serverless, à l’instar de l’intelligence artificielle ou de la réalité virtuelle, est une des grandes tendances identifiées par le Gartner en 2017. Tant elle va impacter les DSI, modifier les pratiques des devs et des ops ainsi qu’améliorer le delivery, le serverless sera cette révolution qu’il ne faudra pas rater et ce dès 2018. Il est donc important de se positionner pour aider au mieux les acteurs qui souhaitent y prendre part.