
Panorama des solutions de big data L'architecture HDFS
Parmi les composants Hadoop, HDFS est au cœur de la distribution des données sur de multiples serveurs, dont le nombre peut atteindre plusieurs milliers pour une volumétrie totale de plusieurs centaines de téraoctets. Compte tenu du nombre important de serveurs, la probabilité d'apparition d'une panne hardware est très forte. HDFS est capable de détecter ces erreurs rapidement et automatiquement. La figure 4.2 illustre le fonctionnement de HDFS.
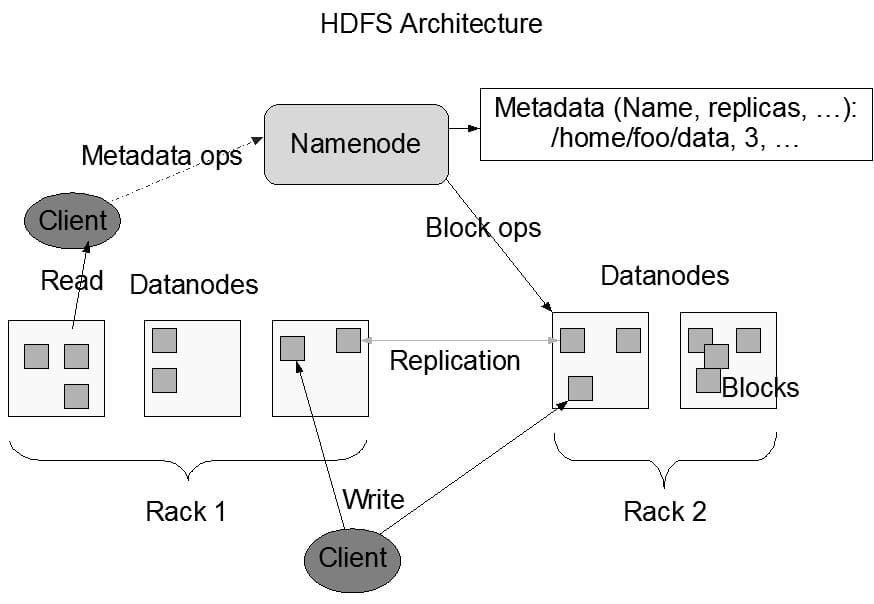
Pour un cluster, il existe un unique Namenode qui supervise l'espace de nommage et reçoit les requêtes de consultation des données. Le Namenode exécute les opérations d'ouverture, de fermeture, changement de nom de fichier ou de répertoire. Chaque espace de stockage est géré par un Datanode. Les fichiers de base de données sont découpés en blocs de taille fixe de 64 Mo et stockés au sein des Datanodes. Les Datanodes se chargent des requêtes de lecture et d'écriture. Ils effectuent également les opérations de création, réplication ou suppression de fichiers. Les clients communiquent à la fois avec le Namenode et le Datanode.