
Avec Gemma 3n, Google miniaturise l'intelligence artificielle de pointe


L'équipe chargée de la famille open source Gemma chez DeepMind a présenté à l'occasion de Google I/O 2025 Gemma 3n, son nouveau SLM de référence et très probablement celui du marché. Le modèle, entièrement multimodal (texte, audio, vidéo, image), a été conçu pour être inféré sur CPU.
Une nouvelle architecture made in DeepMind
La famille Gemma tire parti de l'ensemble des améliorations de son grand frère propriétaire, Gemini. Pour Gemma 3n, les ingénieurs de DeepMind sont allés encore plus loin et ont développé une nouvelle architecture optimisée pour l'inférence sur appareil avec des capacités hardware limitées. La principale innovation, appelée Per-Layer, permet de drastiquement limiter la consommation de RAM du modèle. Par défaut, le modèle possède 5 et 8 milliards de paramètres selon la version utilisée mais avec le Per-Layer, Gemma 3n s'exécute avec une empreinte mémoire comparable à des modèles de 2 et 4 milliards de paramètres. Techniquement, la technique du Per-Layer Embeddings permet de réduire dynamiquement l'utilisation de la mémoire vive en optimisant les représentations de chaque couche du modèle.
L'architecture de DeepMind introduit également le MatFormer, qui permet d'intégrer nativement un sous-modèle de 2 milliards de paramètres. Le but ? Utiliser un sous-modèle avec une taille optimisée en fonction de la complexité de la tâche et réduire ainsi les besoins en ressources. Les développeurs peuvent par ailleurs créer plusieurs tailles de sous-modèle dans Gemma 3n selon leurs besoins.
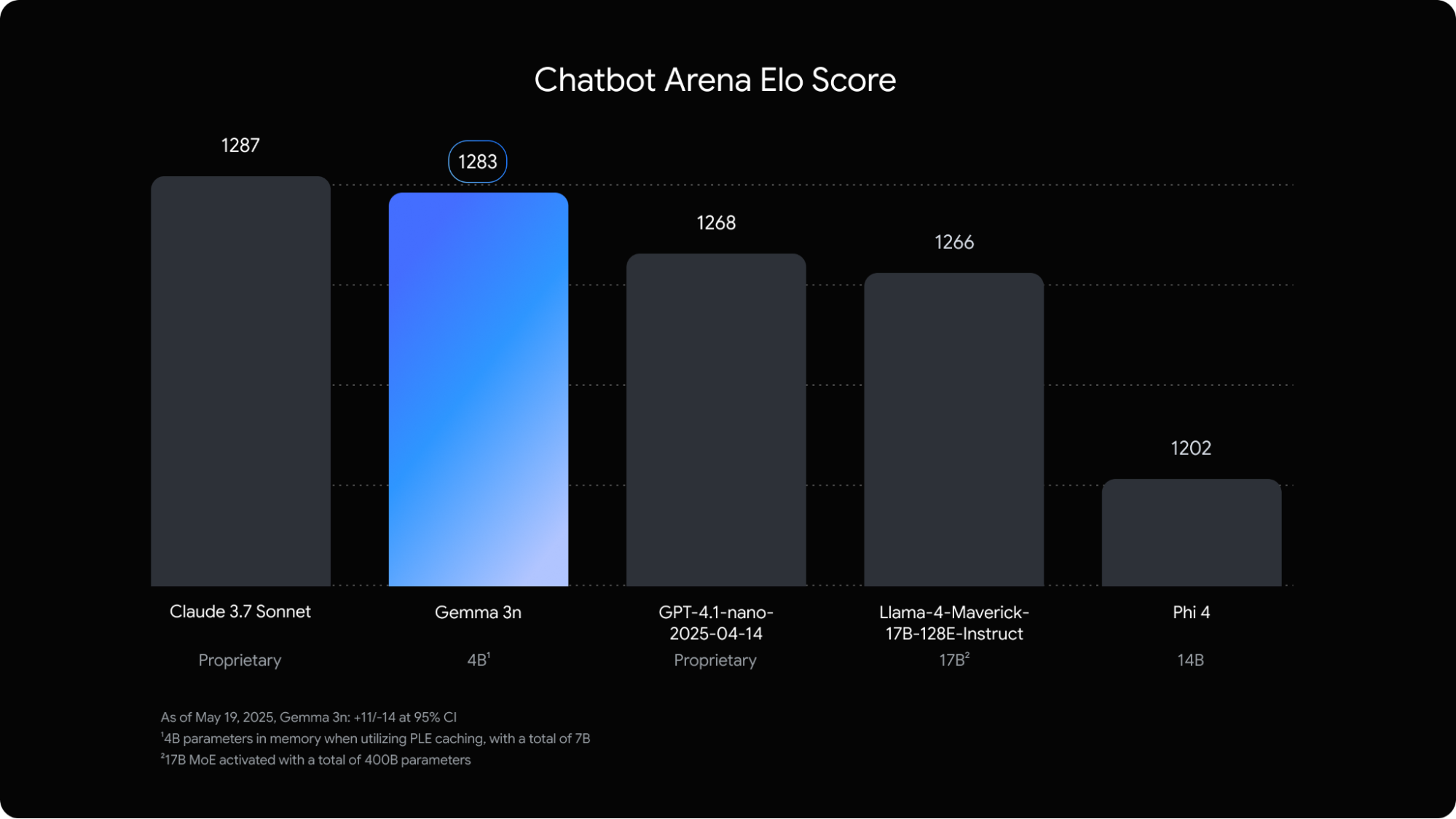
Gemma 3n, proche de Claude 3.7 Sonnet dans la Chatbot Arena
Gemma 3n fait très fort dans les benchmarks, en particulier au vu de sa petite taille. Sur la Chatbot Arena, qui mesure les préférences des utilisateurs de façon anonymisée, Gemma 3n obtient un score Elo de 1269, le plaçant juste derrière Claude 3.7 Sonnet (1289) et devant GPT-4.1 ou Llama-4-Maverick-17B. Un petit exploit.
Sur les benchmarks plus classiques Gemma 3n affiche des résultats solides avec 64,9% sur MMLU, 63,6% de réussite sur MBPP, et 75,0% de réussite sur HumanEval. Si on le compare aux modèles de taille équivalente, Gemma 3n devient alors SOTA sur la majorité des benchmarks. Une prouesse pour un modèle qui dispose en plus d'une taille réduite à l'inférence. Par exemple, alors que Phi-3 (14B) de Microsoft nécessite près de 14 milliards de paramètres pour atteindre un score MMLU d'environ 62%, Gemma 3n utilise effectivement seulement 4 milliards de paramètres actifs pour atteindre 64,9%.
L'inférence en local ou depuis le cloud
Gemma 3n est désormais disponible dans Google AI Studio pour le moment gratuitement, comme l'ensemble des modèles Gemma. Les poids du modèle peuvent également être téléchargés sur Hugging Face. Seule limitation, la version actuellement déployée ne permet de traiter que les modalités texte et images. Google prévoit toutefois de mettre à jour les poids avec l'ensemble des modalités dans les prochaines semaines.
Pour la version open source, les poids sont protégés par la licence générale des modèles Gemma. Le modèle peut être utilisé à des fins commerciales sans frais de licence ou redevances à Google. Par ailleurs, Google se réserve le droit de restreindre l'utilisation du modèle s'il estime raisonnablement que celle-ci viole les conditions d'utilisation. Il est notamment interdit d'utiliser le modèle pour la génération de contenus protégés par copyright, de contenus illégaux. Plus restrictif, il est également interdit d'utiliser Gemma 3n pour "la prise de décisions automatisées" dans des domaines qui "affectent les droits matériels ou individuels ou le bien-être" comme "la finance, le juridique, l'emploi, les soins de santé, le logement, l'assurance ou encore l'aide sociale."
Gemma 3n s'impose comme la nouvelle référence du SLM open source. Google recommande notamment son utilisation pour la génération de texte, l'utilisation en mode chatbot, le résumé d'informations, l'analyse visuelle ou encore la transcription ou analyse de fichier audio. Son optimisation pour l'inférence sur mobile (seulement 3924 Mo de ram) en fait un modèle parfait pour expérimenter de nouveaux usages.