
Puissant, rapide, frugal... K2 Think, la nouvelle référence du raisonnement open source


Après avoir recruté massivement des ingénieurs de haut niveau en IA (y compris en France), les Émirats récoltent déjà les fruits de leur stratégie. La Mohamed bin Zayed University of Artificial Intelligence et la start-up locale spécialisée en IA G42 ont présenté mardi 9 septembre, K2 Think, un modèle de raisonnement frontière, open source, à seulement 32 milliards de paramètres. L'IA concurrence dans les benchmarks des modèles jusqu'à 20 fois plus grands. Une petite prouesse.
Un modèle excellent en mathématiques
K2-Think frappe fort sur les benchmarks mathématiques. Sur les compétitions les plus exigeantes comme AIME 2024 et 2025, le modèle atteint respectivement 90,83% et 81,24%, dépassant même le dernier modèle open source d'OpenAI, GPT-OSS 120B (89,58% et 84,59%) et DeepSeek v3.1 671B (91,87% et 82,49%). Côté science et programmation, sur LiveCodeBench, K2-Think obtient 63,97%, surpassant nettement Qwen3-235B-A22B (56,64%) mais restant en retrait face à GPT-OSS 120B (74,53%). En sciences, avec 71,08% sur GPQA-Diamond, il se maintient dans la moyenne haute sans pour autant dominer.
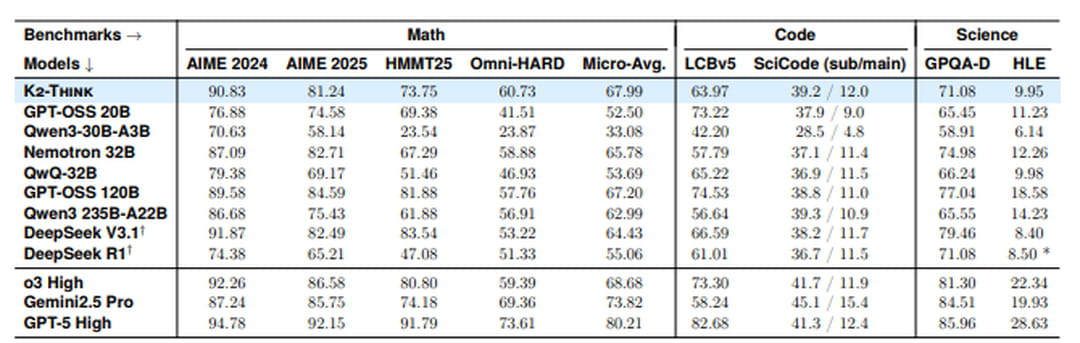
En revanche, les chercheurs ne cachent pas leur parti pris : plutôt que de communiquer sur des benchmarks généralistes où K2-Think afficherait, surement des performances moyennes, ils mettent délibérément l'accent sur sa capacité de "frontière" en mathématiques.
K2-Think n'est donc pas conçu pour être utilisé comme un modèle généraliste. En revanche ses excellentes capacités en mathématiques en font un modèle de choix pour les cas d'usage autour de l'analyse et la manipulation de données, l'optimisation ou encore la simulation. K2-Think peut se révéler un excellent agent d'analyse data au sein d'un système agentique, par exemple.
Le vrai point fort de K2 Think
Les chercheurs ont d'abord entraîné le modèle de base Qwen2.5-32B (en fine-tuning supervisé) à produire des "chaînes de pensée" détaillées, c'est-à-dire en explicitant étape par étape son raisonnement plutôt que de donner directement la réponse. Le modèle apprend alors à structurer sa réflexion. Les chercheurs ont ensuite appliqué de l'apprentissage par renforcement (récompense pour les réponses correctes).
Mais l'astuce principale intervient pendant l'utilisation du modèle. K2-Think ne se contente pas de répondre directement : il commence par créer un plan de résolution, génère trois réponses différentes, puis sélectionne automatiquement la meilleure. Contre-intuitivement, cette étape de planification raccourcit les réponses de 12% tout en les rendant plus précises. Résultat, K2 Think obtient des performances à la hauteur de modèles faisant jusqu'à 20 fois sa taille.
Les poids disponibles en open source (Apache 2)
Les chercheurs émiratis ont mis les poids de K2-Think à disposition sur Hugging Face sous licence Apache 2.0, la plus permissive du marché. Pour l'inférer il sera nécessaire de disposer d'environ 60 à 70 Go de VRAM. La configuration classique : un H100 ou un A100 pour exécuter la version la moins compressée.
Pour tester immédiatement les capacités du modèle, une interface de chat dédiée est disponible sur k2think.ai. Comme Mistral AI, les Emiratis ont choisi de déployer leur service sur les processeurs Cerebras. L'infrastructure permet d'obtenir des temps de réponse très courts : là où un GPU traditionnel prendrait près de 3 minutes pour générer une réponse complexe de 32 000 tokens, K2-Think (avec Cerebras) la génère en 16 secondes.
K2-Think représente une opportunité rare pour les entreprises, disposer d'un modèle de raisonnement de niveau "frontière" tout en gardant le contrôle total sur leurs données sensibles. Sa licence Apache 2.0 permet en effet un déploiement en interne sans restriction (et c'est notable). Plus encore, les entreprises peuvent fine-tuner le modèle sur leurs propres données sectorielles pour créer des assistants spécialisés, le tout à coût relativement maitrisé.