
Tutoriel : comment installer son propre ChatGPT gratuit en quelques minutes sur son ordinateur


2026 sera-t-elle l'année de l'IA on-device? La fin d'année 2025 a connu son lot d'outils pour créer des agents et chatbots exécutés en local sur sa propre machine. Parmi eux, la nouvelle interface de la célèbre librairie d'inférence llama.cpp a été entièrement recodée pour être facile à utiliser avec d'excellentes performances, quel que soit le device utilisé. La WebUI (interface graphique) de llama.cpp a, en effet, été entièrement réécrite par Georgi Gerganov, pilier de la communauté open source sur GitHub. Outre le changement d'interface (plus simple) et l'amélioration des performances globales (grâce au changement de langage de développement), la nouvelle mouture intègre une gestion avancée des fichiers, le support du raisonnement, et l'utilisation de branches pour les conversations. Comment l'installer et l'utiliser ? Tutoriel.
1. Installer llama.cpp
Le premier ré-requis à l'utilisation de WebUI est l'installation de llama.cpp (pour ceux qui ne l'ont jamais installé). L'installation se fait assez simplement, sur Windows, Mac et Linux.
- Pour Windows, il faut utiliser le gestionnaire de packages WinGet avec la commande : winget install llama.cpp dans votre terminal (CMD).
- Pour Apple (notre cas) et Linux, le plus simple est d'utiliser le gestionnaire Homebrew : brew install llama.cpp
L'installation est rapide et prend quelques minutes, selon votre débit Internet.
2. Téléchargement du modèle et lancement du serveur
L'installation de llama.cpp étant faite, le package contient déjà l'ensemble du code de WebUI. L'équipe de llama.cpp a accepté le merge de Georgi Gerganov, et le package contient donc tout le nécessaire, pas besoin d'installation complémentaire.
Une seule commande est nécessaire pour télécharger, inférer le modèle et lancer ensuite le serveur web. La voici : llama-server -hf LiquidAI/LFM2.5-1.2B-Instruct-GGUF --host 127.0.0.1 --port 8033
Dans le cadre de ce test, nous utilisons LFM2.5-1.2B-Instruct-GGUF. Mais vous pouvez tout à fait utiliser un autre modèle en fonction de la taille de la VRAM disponible sur votre machine. Il suffit de remplacer LiquidAI/LFM2.5-1.2B-Instruct-GGUF par le nom du dépôt Hugging Face de votre modèle (souvent le nom de l'éditeur ou le pseudo de l'utilisateur ayant optimisé les poids) suivi du nom du modèle choisi. Attention, il faut impérativement un modèle avec les poids au format GGUF. Pour choisir le modèle adapté à votre machine, n'hésitez pas à lire notre article dédié (LLM en local : comment choisir la bonne configuration matérielle ?).
Enfin, si vous utilisez un serveur distant (VPS, serveur dédié...), il est également possible de changer l'adresse IP et le port du serveur web, par exemple pour exposer l'interface de WebUI en externe avec 0.0.0.0 (attention à bien configurer un pare-feu et un reverse proxy ou une limitation par adresse IP).
3. Utiliser l’interface, depuis le web
Une fois la commande envoyée, l'interface WebUI de llama est disponible en local à l'adresse : http://127.0.0.1:8033. C'est aussi simple que cela.

Une fois sur la page web du serveur, l'interface s'affiche. Cette dernière est très proche de ChatGPT, idéale pour les personnes habituées aux interfaces simples et fonctionnelles. Il est possible de saisir un prompt mais également d'envoyer des PDF, des documents textes, des images ou encore des fichiers vocaux pour peu que le modèle choisi soit multimodal.
Votre modèle utilisera alors prioritairement le document fourni pour répondre. Le tout en local, de façon sécurisée et assez rapidement selon la taille du modèle. Avec LFM2.5-1.2B-Instruct-GGUF, modèle de 1,2 milliard de paramètres sur notre Mac Mini avec 24 Go de RAM, nous obtenons une vitesse comprise entre 80 et 100 tokens par seconde, c'est bien plus rapide que GPT-5 Instant ou Gemini 3 Flash (évidemment les performances ne sont absolument pas comparables) pour du traitement de texte.
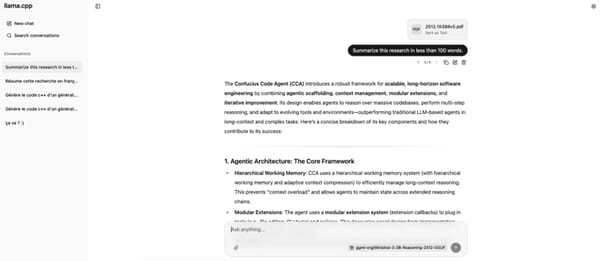
L'interface propose également des réglages de base pour optimiser les réponses du modèle : temperature, Top K, Top P, etc. Enfin, toutes les conversations sont enregistrées, comme sur ChatGPT, Claude ou Gemini, dans la partie gauche de l'interface et stockées localement sur votre ordinateur.
Une interface basique mais fonctionnelle
WebUI de llama.cpp coche toutes les cases pour les utilisateurs qui ne veulent pas des installations et configurations compliquées. C'est simple, fonctionnel, et surtout, les données restent sur le PC. Il est même possible d'automatiser le démarrage du serveur sous Windows. Il suffit de créer un fichier .bat avec la commande llama-server -hf ggml-org/Ministral-3-3B-Reasoning-2512-GGUF --host 127.0.0.1 --port 8033, de le placer dans le dossier de démarrage de Windows (accessible via Win+R puis shell:startup), et d'ajouter http://127.0.0.1:8033 dans vos favoris. Résultat : votre serveur IA démarre automatiquement avec votre PC et reste accessible en permanence d'un simple clic dans le navigateur. Pratique.
Seul bémol, l'interface ne propose pas encore de support natif du protocole MCP ni d'outils préconfigurés comme la recherche web ou l'accès à des APIs externes, contrairement à d'autres solutions comme LM Studio. Pour l'instant, WebUI se concentre sur l'essentiel : discuter avec le modèle et gérer des fichiers. Mais rien n'empêche que ces fonctionnalités soient implémentées par la suite, surtout vu l'activité de la communauté open source autour de llama.cpp. En attendant, pour un usage local, sécurisé et sans dépendance au cloud, WebUI fait déjà très bien le job.