
RAG vs MCP : le guide complet pour construire des assistants IA fiables

Les grands modèles de langage (LLM) ont transformé la manière dont nous interagissons avec l'information. Mais lorsqu'on cherche à les déployer en production dans des contextes métier réels, des limites arrivent rapidement.
1. Mise en contexte : pourquoi ce débat existe
Les grands modèles de langage (LLM) ont transformé la manière dont nous interagissons avec l’information. Mais lorsqu’on cherche à les déployer en production dans des contextes métier réels, leurs limites structurelles apparaissent rapidement : hallucinations, informations périmées, contexte incomplet. Un LLM « en vase clos » — c’est-à-dire sans accès à des sources externes — reste un outil puissant mais incomplet.
Face à ce constat, deux approches distinctes ont émergé pour étendre les capacités des LLM :
• Le RAG (Retrieval-Augmented Generation) : amener de l’information pertinente au modèle au moment de la génération.
• Le MCP (Model Context Protocol) : connecter le modèle à des capacités et des sources via une interface standardisée.
Ces deux approches ne sont pas des concurrentes directes — elles répondent à des problèmes différents. L’objectif commun reste cependant le même : réduire l’incertitude, augmenter la fiabilité des réponses et industrialiser l’usage de l’IA dans les organisations.
2. Définitions claires
2.1 RAG (Retrieval-Augmented Generation)
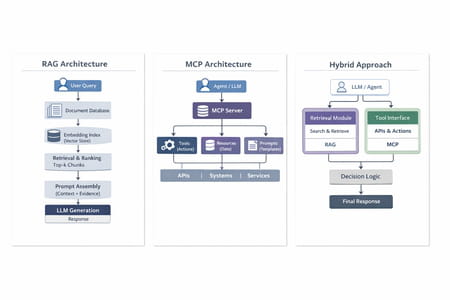
Le RAG est une architecture dans laquelle le modèle de langage n’opère pas seul : avant de générer une réponse, un système de recherche extrait les passages les plus pertinents depuis un corpus de documents, puis les injecte dans le prompt.
Le pipeline typique se décompose ainsi :
• Recherche dans un corpus (documents, pages, tickets, specs…)
• Sélection des passages les plus pertinents (top-k)
• Injection de ces passages dans le contexte du prompt
• Génération de la réponse par le LLM
Ce que le RAG apporte : de la connaissance, au sens documentaire du terme. Ce qu’il ne fait pas : exécuter des actions, orchestrer des outils ou garantir l’exactitude absolue de la réponse.
2.2 MCP (Model Context Protocol)
Le MCP est un protocole standardisé qui permet à un modèle de langage de communiquer avec des serveurs exposant des outils, des ressources et des templates de prompts. Il ne s’agit pas d’une technique de recherche, mais d’une couche d’intégration.
Un serveur MCP peut exposer :
• Des outils (tools) : actions exécutables comme créer un ticket, lancer un job, lire un KPI.
• Des ressources (resources) : données accessibles en lecture depuis des systèmes tiers.
• Des prompts (prompts) : templates et best practices préconfigurés.
Ce que le MCP apporte : de la connectivité standardisée. Ce qu’il ne fait pas : choisir lui-même le meilleur passage dans un corpus de documents — il expose, il n’infère pas.
3. Le vrai sujet : connaissance vs capacités
Si l’on devait résumer la distinction fondamentale en une phrase : le RAG est un système de preuve, le MCP est un système d’intégration.
Le RAG permet au modèle de s’appuyer sur des évidences documentaires pour construire une réponse. Le MCP lui permet d’agir sur des systèmes vivants et d’y lire des données en temps réel. Ces deux besoins sont souvent présents simultanément dans les cas d’usage métier avancés, ce qui explique pourquoi RAG et MCP sont fréquemment complémentaires plutôt qu’exclusifs.
4. Architecture : comment ça marche concrètement
4.1 Pipeline RAG de bout en bout
Une architecture RAG complète en production comprend plusieurs étapes :
• Ingestion : collecte des documents sources (PDF, pages web, tickets, notes internes…)
• Chunking : découpage des documents en segments de taille optimale pour la recherche
• Embeddings : transformation de ces segments en vecteurs numériques par un modèle d’encodage
• Indexation : stockage de ces vecteurs dans un index (vector store)
• Retrieval : à chaque requête, recherche des passages les plus proches sémantiquement (top-k)
• Re-ranking et filtrage : amélioration de la pertinence des résultats
• Assemblage du prompt : intégration des passages dans la fenêtre de contexte du LLM
• Génération et post-traitement : production de la réponse avec citations et validations
4.2 Architecture MCP (côté client et côté serveur)
L’architecture MCP repose sur une séparation claire entre le client (le LLM ou l’agent) et les serveurs MCP. Chaque serveur expose un catalogue d’outils et de ressources via une interface standardisée.
Les composantes clés d’une infrastructure MCP incluent : la gestion de l’authentification et des autorisations (AuthN/AuthZ), les politiques d’accès, l’observabilité, le versionning des outils et les catalogues de services. La gouvernance est au cœur du dispositif : sans elle, on aboutit rapidement au phénomène de « tool sprawl » — une proliferation incontrôlée d’outils mal documentés.
5. Cas d’usage : qui gagne quand ?
5.1 Le RAG est le bon défaut quand…
Le RAG s’impose comme choix naturel dans tous les contextes où la connaissance documentaire est centrale :
• FAQ, support client, procédures internes
• Recherche dans de la documentation, des contrats, des spécifications techniques ou des tickets
• Besoin de citations et de traçabilité des réponses
• Knowledge base interne avec contenu stable ou semi-stable
5.2 Le MCP est clé quand…
Le MCP devient indispensable dès qu’il faut agir ou accéder à des systèmes vivants :
• Actions : créer un ticket, lancer un job, lire un KPI en temps réel, modifier une configuration
• Accès à des systèmes transactionnels : CRM, ERP, ITSM, outils de CI/CD, plateformes d’observabilité
• Nécessité de gouverner finement les permissions et de conserver un trail d’audit
5.3 Quand il faut les deux
Les cas d’usage les plus riches combinent RAG et MCP en synergie :
• Assistant Ops / DevOps : RAG pour les runbooks + MCP pour les outils de gestion d’incidents
• Copilot commercial : RAG pour les playbooks + MCP pour le CRM, les données de prix et de stock
• Assistant conformité : RAG pour les politiques internes + MCP pour les outils de contrôle et d’export
6. Design patterns recommandés
Plusieurs patterns architecturaux ont fait leurs preuves en production :
• Evidence-first (RAG) : le modèle ne répond que si des preuves documentaires suffisantes ont été trouvées. En l’absence de contexte pertinent, il refuse de générer.
• Tool-first (MCP) : si la donnée source of truth réside dans un système live, on appelle l’outil en premier, avant même d’envisager le retrieval.
• Hybrid : retrieval d’abord, puis décision sur l’outil à appeler, puis réponse finale enrichie de preuves documentaires.
• Cache & freshness : les documents stables passent par le RAG, les données volatiles par les outils MCP.
• Policy gating : certaines actions ne peuvent être exécutées via MCP qu’après une validation explicite (humain ou règle métier).
7. Points d’attention : là où ça casse en production
7.1 Pièges classiques du RAG
• Chunking médiocre : des segments trop grands ou trop petits dégradent la qualité du retrieval.
• Embeddings inadaptés : un modèle d’encodage mal choisi produit des vecteurs peu représentatifs.
• Index « sale » : des documents obsolètes ou redondants polluent les résultats.
• Retrieval bruité : un top-k trop large injecte du contexte non pertinent, ce qui provoque des hallucinations bien rédigées.
• Contexte trop long ou mal priorisé : le LLM perd le fil dans une fenêtre de contexte surchargée.
• Évaluation insuffisante : sans jeux de tests et métriques de pertinence, les dégradations passent inaperçues.
7.2 Pièges classiques du MCP
• Catalogue non gouverné (tool sprawl) : trop d’outils, mal documentés, dégradent la qualité de la sélection par le modèle.
• Permissions trop larges : en l’absence du principe de moindre privilège, les risques de sécurité s’accumulent.
• Manque d’audit : sans logs d’appels, il est impossible de retracer les actions exécutées par l’agent.
• UX agentique brisée : boucles infinies, appels inutiles, latence cumulée dégradent l’expérience utilisateur.
• Contrats d’API instables : un changement de format en aval provoque des comportements erratiques difficiles à déboguer.
8. Sécurité, conformité et gouvernance
La mise en production d’un système combinant RAG et MCP soulève des enjeux de gouvernance transversaux :
• Données : classification, détection des PII, politiques de rétention, chiffrement au repos et en transit.
• Accès : définition de scopes, principe de moindre privilège, processus d’approbation, MFA sur les outils sensibles.
• Traces : logs complets, audit trails, explicabilité des décisions (pourquoi cet outil a été appelé ?).
• Human-in-the-loop : définir précisément les situations où une validation humaine est obligatoire avant action.
• Multi-vendor : éviter l’enfermement technologique en définissant des standards internes et en maintenant la portabilité.
9. Évaluation et métriques
9.1 Métriques pour le RAG
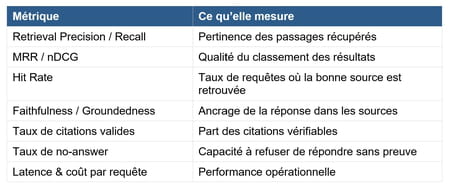
9.2 Métriques pour le MCP / outils

10. Guide de décision
Avant de choisir une architecture, répondez à ces six questions :
• La donnée est-elle documentaire ou transactionnelle / live ?
• Faut-il agir (créer, modifier, déclencher) ou seulement répondre ?
• Y a-t-il une exigence de preuves et de citations dans la réponse ?
• Y a-t-il une exigence de permissions fines et de trail d’audit ?
• Quelles sont les contraintes de latence et de coût ?
• Quelle est la volatilité des données : changement quotidien (outil) ou contenu stable (RAG) ?
Selon les réponses, la sortie sera : RAG seul, MCP seul, ou une architecture hybride avec des priorités d’implémentation clairement définies.
11. Roadmap d’implémentation
Phase 1 : RAG minimal viable
Construire un premier pipeline RAG fonctionnel sur un corpus maîtrisé, définir les métriques d’évaluation de base et mettre en place un jeu de tests de référence. L’objectif est de valider la pertinence du retrieval avant d’ajouter de la complexité.
Phase 2 : MCP pour les outils critiques
Intégrer 2 à 3 outils à forte valeur métier via le protocole MCP. Mettre en place dès le départ le catalogue, les permissions et les logs d’audit. Ne pas sacrifier la gouvernance à la vitesse de livraison.
Phase 3 : Patterns hybrides et garde-fous
Implémenter les patterns hybridés (retrieval + tool routing), ajouter des guardrails métier et définir les règles de routage automatique entre RAG et MCP selon la nature de la requête.
Phase 4 : Industrialisation
Définir des SLO, automatiser les tests de non-régression, mettre en place le monitoring continu du coût et de la qualité. C’est à cette phase que le système devient véritablement opérationnel à l’échelle.
12. Conclusion : MCP vs RAG est un faux duel
Le débat RAG vs MCP est, en réalité, mal posé. Ces deux approches ne s’affrontent pas : elles se complètent.
Le RAG apporte la crédibilité par la preuve : il ancre les réponses dans des sources documentaires vérifiables, réduit les hallucinations et produit des réponses traçables. Le MCP apporte la valeur par l’action et l’intégration : il connecte le modèle au monde réel, lui permettant d’agir sur des systèmes vivants et d’accéder à des données fraîches.
Ensemble, ils permettent de construire des assistants IA qui sont à la fois fiables (ancrés dans des preuves), utiles (capables d’agir) et gouvernables (traçables, sécurisés, auditable). C’est cette triple propriété qui distingue les systèmes IA production-ready des prototypes convaincants.
Le bon point de départ n’est pas « RAG ou MCP ? » mais « quelle est la nature de la donnée et de l’action attendue ? ». La réponse à cette question détermine l’architecture. Et dans la plupart des cas d’usage métier avancés, la réponse est : les deux.