
Comment installer et configurer gratuitement votre propre agent de code en local avec Continue


Continue est une extension installable dans VS Code et qui permet de coder hors ligne et gratuitement. Elle lit votre code, écrit du nouveau code et exécute des commandes quand vous lui dites quoi faire en français ou en anglais. Aucune donnée de vos projets n’est transmise hors de votre ordinateur, garantissant la confidentialité de vos projets.
Les prérequis
Afin d’utiliser l’extension Continue, deux logiciels, Ollama et Visual Studio Code, doivent être préalablement installés. Ollama va nous permettre d’exécuter des modèles d’IA en local et VS Code de créer du code. C’est sur cette interface que nous allons pouvoir utiliser un modèle d’IA spécialisé dans le codage.
Rendez-vous sur https://ollama.com et téléchargez la version correspondant à votre système d'exploitation (Windows, macOS ou Linux). Une fois le téléchargement terminé, lancez l'installateur et suivez les instructions.
Téléchargez VS Code depuis https://code.visualstudio.com et installez-le sur votre machine.
L’installation
Dans VS Code, cliquez sur “Extensions” et installez l’extension “Continue”. Une fois l'extension installée et ouverte, une fenêtre de configuration devrait apparaître. Sélectionnez l'option “Local”. Si Ollama est correctement installé et en cours d'exécution, Continue vous proposera de télécharger plusieurs modèles d'IA via des lignes de commande. Vous pouvez choisir de télécharger tous les modèles suggérés ou de sélectionner ceux qui correspondent le mieux à vos besoins. Une fois les modèles installés, ils seront utilisables par l’intermédiaire de l’application mais aussi directement sur Ollama par son interface de chat.
Si les modèles conseillés peuvent évoluer au cours du temps en fonction des performances, les modèles sont divisés en trois catégories : les modèles chat qui sont optimisés pour des conversations (comme Llama), les modèles “autocomplete” conçus pour la complétion de texte en temps réel (ici du code, avec Qwen Code) et les modèles d’embedding qui génèrent des vecteurs numériques à partir de texte, facilitant le travail de l'IA en arrière-plan pour comprendre le contexte de votre code

Choisir le bon modèle
Lors de l’utilisation d’un modèle pour la génération ou la complétion de code, vous devez choisir la taille ou dimension du modèle ainsi que certains paramètres d’exécution selon vos besoins et les ressources dont vous disposez. Des modèles tels que Qwen2.5-Coder illustrent bien cette flexibilité : la version 7B (7 milliards de paramètres) est idéale pour la performance, mais nécessite environ 5-8 Go de VRAM/RAM. Si vous privilégiez la rapidité ou disposez de moins de mémoire, la déclinaison en 1,5B constitue une alternative plus légère.
Le modèle 32B, plus imposant, se rapproche des performances de GPT‑4o, mais nécessite davantage de ressources matérielles. Si votre machine dispose d’un GPU compatible (NVIDIA CUDA ou AMD ROCm), veillez à ce qu’Ollama l’utilise bien pour l’inférence des modèles, car l’accélération GPU améliore considérablement la vitesse de génération.
Les différentes fonctionnalités
Continue offre quatre modes principaux :
- L'Autocomplete fournit des suggestions de code intelligentes et contextuelles directement pendant que vous tapez votre code. Il anticipe ce que vous voulez écrire et vous propose des complétions que vous pouvez accepter en cliquant sur la touche “Tab”. Pour l'utiliser efficacement, donnez des noms de fonctions clairs et ajoutez des commentaires explicatifs pour fournir un maximum de contexte à l'IA.
- Le mode Edit vous permet d'apporter des modifications précises à des sections de code spécifiques. Sélectionnez simplement le code que vous souhaitez modifier, appuyez sur “Cmd/Ctrl + I” et décrivez le changement désiré (par exemple, "rendre ce code plus lisible"). Continue vous montrera ensuite les modifications proposées, que vous pourrez accepter ou rejeter.
- Le mode Chat est un assistant IA qui peut analyser votre code et répondre à vos questions. Vous pouvez lui demander d'expliquer un algorithme, de suggérer des optimisations, d'écrire des tests, ou même de brainstormer des solutions à des problèmes précis. Pour interagir avec le mode Chat : appuyez “Cmd/Ctrl + L”.
- Le mode Agent est un assistant de codage autonome capable de lire des fichiers, d'apporter des modifications, d'exécuter des commandes et de gérer des tâches complexes en plusieurs étapes. Le mode agent analyse votre code existant, crée les fichiers nécessaires, écrit le code, gère les configurations et vous explique chaque étape de son processus.
Le test pratique
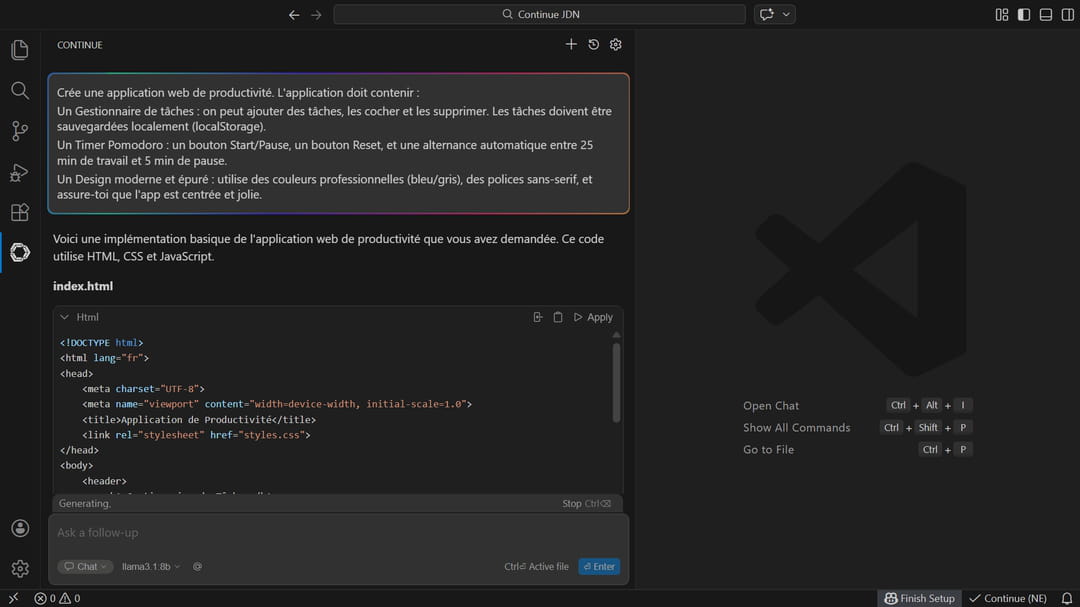
Nous allons tester la création d’une petite application interactive. Voici le prompt :
Génère une application web de productivité. L’application doit contenir : Un gestionnaire de tâches : on peut ajouter des tâches, les cocher et les supprimer. Les tâches doivent être sauvegardées localement (localStorage) Un Timer Pomodoro : un bouton Start/Pause, un bouton Reset, et une alternance automatique entre 25 minutes de travail et 5 min de pause. Un Design moderne et épuré : utilise des couleurs professionnelles (bleu/gris), des polices sans-serif, et assure-toi que l'app est centrée et jolie.
En moins de 4 minutes, Continue a généré trois fichiers fonctionnels. Ce temps de traitement a été rapide pour ce test qui ne comprenait que quelques dizaines de lignes de code.
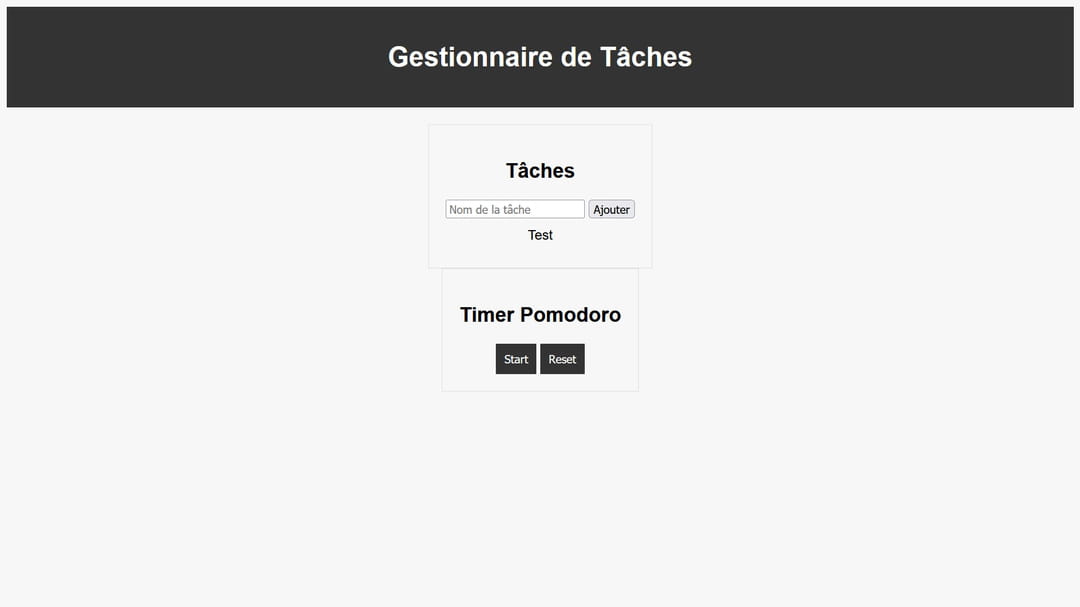
L'extension Continue, combinée à Ollama et des modèles comme Qwen Code, a une bonne efficacité. Elle offre un outil de codage IA gratuit et confidentiel, et cela peut être pertinent aussi pour de l'analyse de données en local. La limite est principalement liée à la puissance de votre ordinateur. Plus celui-ci est puissant, plus vous allez pouvoir faire tourner des modèles qui le sont, ce qui améliorera considérablement la rapidité et la pertinence du code généré.