
Token Monster, le service qui sélectionne la meilleure IA à chaque requête


Et s'il devenait plus facile de choisir le bon modèle adapté au bon cas d'usage ? C'est l'ambition de Token Monster, un side project lancé par Matt Shumer, l'emblématique CEO d'HyperWrite. L'outil s'inspire des agents de code en ligne de commande qui permettent de choisir le meilleur modèle automatiquement pour réaliser des tâches de développement. "Nous avons souhaité disposer d'un outil, qui faciliterait le choix du modèle le plus pertinent pour chaque usage, y compris hors du développement. De nombreux utilisateurs sont prêts à investir davantage pour accéder aux meilleurs résultats", explique Matt Shumer.
Comment fonctionne Token Monster ?
Raisonnement, génération de code, génération de texte… Chaque LLM disponible sur le marché est aujourd'hui excellent sur une ou plusieurs verticales. Pour obtenir les meilleurs résultats, il est donc nécessaire de combiner plusieurs modèles. C'est le principe même de Token Monster. L'outil se présente sous la forme d'un chatbot classique et combine 7 modèles. GPT-4.1 pour le code, Claude Sonnet 4, Opus 4 et Sonnet 3.5 pour la génération de texte, de code et les requêtes créatives, Gemini 2.5 Pro pour le raisonnement et la génération de code et enfin Sonar deep research et sonar de Perplexity pour la recherche web et la recherche avancée.
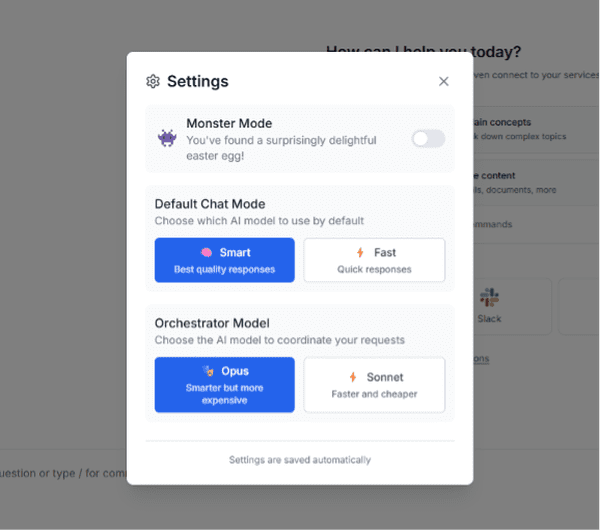
Lorsque l'utilisateur lance sa requête, un modèle orchestrateur (Opus ou Sonnet selon la configuration souhaitée) génère un plan d'action avant de débuter la réponse. Un ou plusieurs modèles sont appelés en fonction de la tâche souhaitée. Le mécanisme automatique de sélection du modèle le plus approprié n'est toutefois pas public, dommage. Le tout est parfaitement transparent pour l'utilisateur final. Token Monster dispose également de nombreux connecteurs pour que l'IA puisse interroger et agir sur le monde réel. On retrouve ainsi Gmail, Slack, GitHub, Notion, une grande partie de la suite Google (Drive, Sheets, Calendar, Docs) ou encore Zendesk. Une seule requête peut déclencher une séquence d'actions, comme une phase de recherche, suivie d'une analyse, d'une rédaction et d'un affinement, potentiellement en utilisant différents LLM à chaque étape.
Token Monster permet de configurer le mode de chat par défaut : "Smart" pour des réponses plus précises et "Fast" pour optimiser la latence. L'interface permet également de choisir son modèle forchestrateur, Claude 4 Opus pour des prompts complexes ou nécessitant un grand nombre d'étapes et Claude Sonnet 4 pour des réponses plus rapides. A noter également qu'utiliser Opus en orchestrateur vous coûtera plus cher, nous y reviendrons.
Le point noir de Token Monster
Token Monster s'avère particulièrement utile sur des cas d'usage complexes ou nécessitant plusieurs étapes pour parvenir au résultat final. La rédaction de rapport avec des informations récentes et/ou sourcées, la génération de code pour un projet avec un haut niveau de complexité sont deux exemples pertinents d'usage de Token Monster.
Nous avons par exemple demandé à Token Monster de générer le code d'un widget un peu complexe (prévision de trafic entre un point A et un point B). L'IA a alors généré un plan des actions à entreprendre pour parvenir au résultat. Token Monster délègue ensuite à sonar de Perplexity la recherche des informations sur les API à utiliser, l'architecture du widget est ensuite déléguée à Gemini 2.5 Pro et le code de chaque fichier est généré par Claude 4 Sonnet. Token Monster nous donne ensuite le code et une petite documentation pour utiliser le widget. Trois modèles auront ainsi été utilisés.