
Dette technique : quel modèle d'IA génère le code le plus maintenable ?

L'IA permet désormais de générer du code à un rythme sans précédent, mais la maintenabilité est une tout autre affaire. L'essor du vibe coding en entreprise a encore accéléré le problème : plutôt que de produire du code maintenable par défaut, les agents d'IA génèrent du code fonctionnel sans intégrer nativement les contraintes de long terme. Installation systématique de dépendances tierces, réécriture complète de stacks existantes… les dérives sont légion. Un vrai mur pour les entreprises, qui dépend notamment du modèle sous-jacent. Selon des chercheurs de la Sun Yat-sen University et d'Alibaba, tous les LLM ne génèrent pas la même qualité de code sur la durée. Et les résultats de leur recherche sont surprenants.
SWE-CI, pour évaluer la maintenabilité du code
Pour classer et évaluer la maintenabilité du code généré par les LLM, les chercheurs ont développé un nouveau benchmark 0 : SWE-CI. L'approche diffère des benchmarks de code classiques type SWE-bench, où l'agent reçoit un bug et génère un patch en one-shot. Avec SWE-CI, on ne demande plus à l'IA de résoudre un problème ponctuel, mais de maintenir un logiciel dans la durée. Concrètement, on prend un vrai projet logiciel open source (extrait de GitHub) et on donne à l'IA sa version d'il y a plusieurs mois. Sa mission : le faire évoluer jusqu'à sa version actuelle, fonctionnalité par fonctionnalité, en enchaînant des dizaines de cycles de modifications. En moyenne, l'écart entre les deux versions représente 233 jours de développement humain. Le dataset final comprend 100 tâches tirées de 68 projets Python matures et reconnus par la communauté développeur.
Côté évaluation, le modèle ne reçoit pas la liste des modifications à faire : il doit les découvrir lui-même. A chaque cycle, il analyse l'écart entre sa version du code et la version cible, identifie les problèmes prioritaires, puis les corrige. Ce cycle se répète jusqu'à 20 fois par tâche. Les chercheurs notent le résultat avec une métrique maison, l'EvoScore, qui valorise surtout la qualité du code en fin de parcours. Un modèle qui produit du code propre et bien structuré dès le début aura encore de la marge de manœuvre en fin de parcours, tandis qu'un modèle qui empile des rustines finira par s'effondrer sous son propre poids.
Claude Opus 4.6 et GLM-5 dans le haut du classement
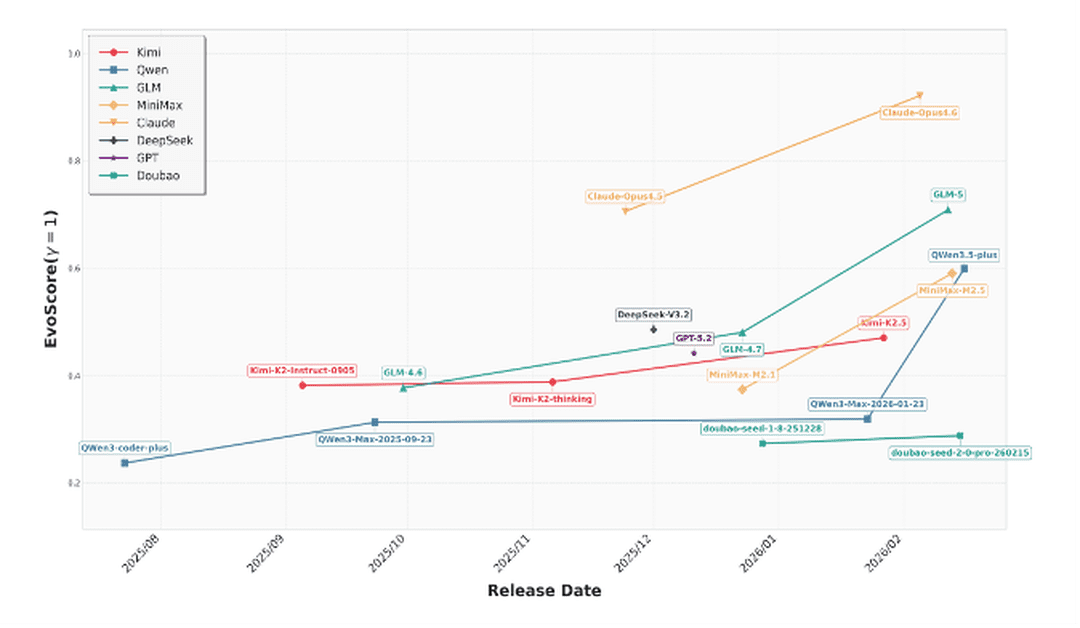
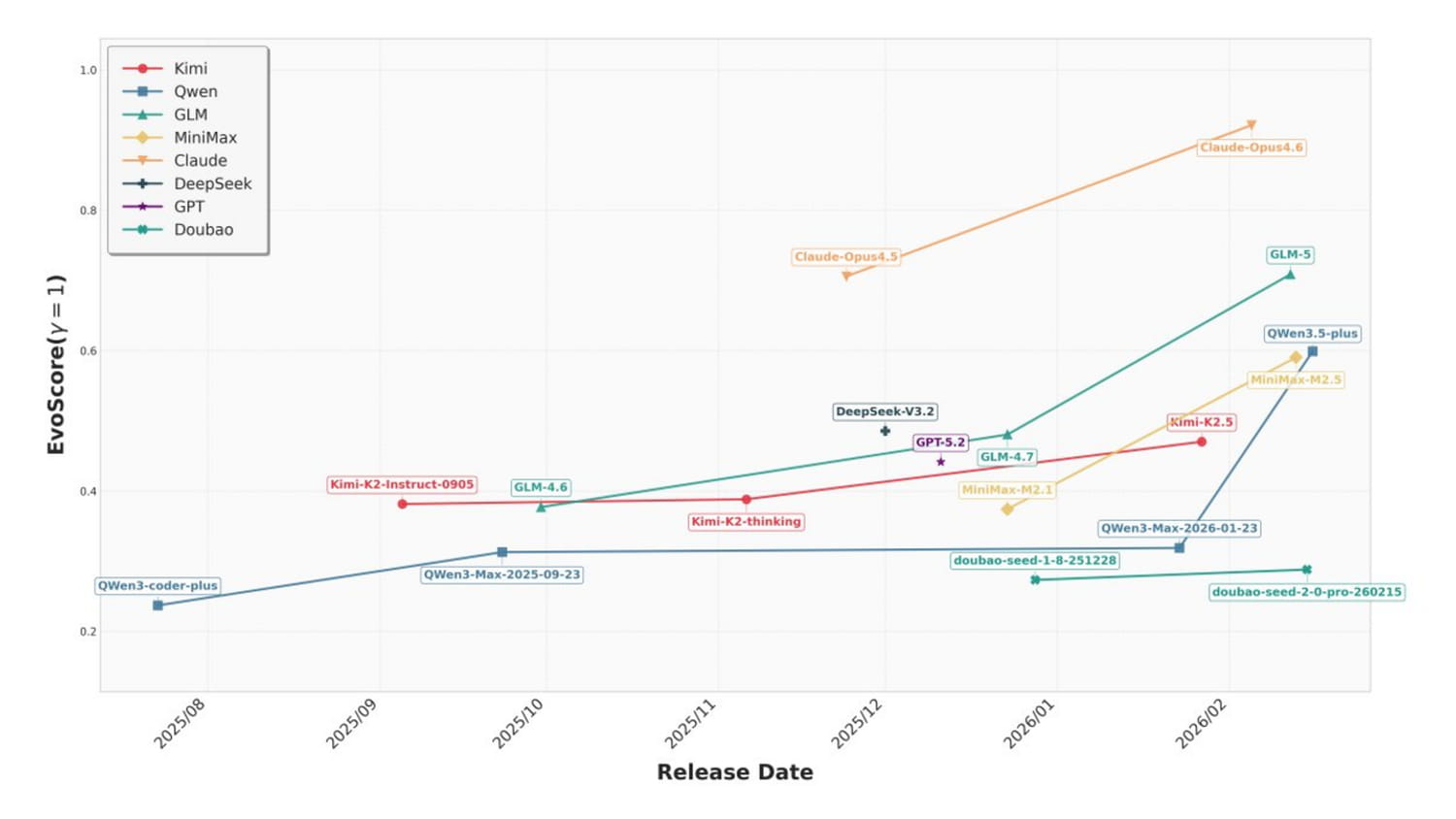
18 modèles de 8 fournisseurs différents ont été passés au crible. Claude Opus 4.6 domine largement le classement avec un score estimé autour de 0.85-0.90, loin devant le reste du peloton. Claude Opus 4.5 et GLM-5 suivent dans une fourchette de 0.60-0.65, formant un deuxième tier. Viennent ensuite Qwen3.5-plus, MiniMax-M2.5 et Kimi-K2.5 autour de 0.45-0.50, puis DeepSeek-V3.2 et GPT-5.2 en milieu de tableau. Au sein de chaque fournisseur, les modèles les plus récents font systématiquement mieux que leurs prédécesseurs, avec une accélération marquée pour ceux sortis après début 2026.
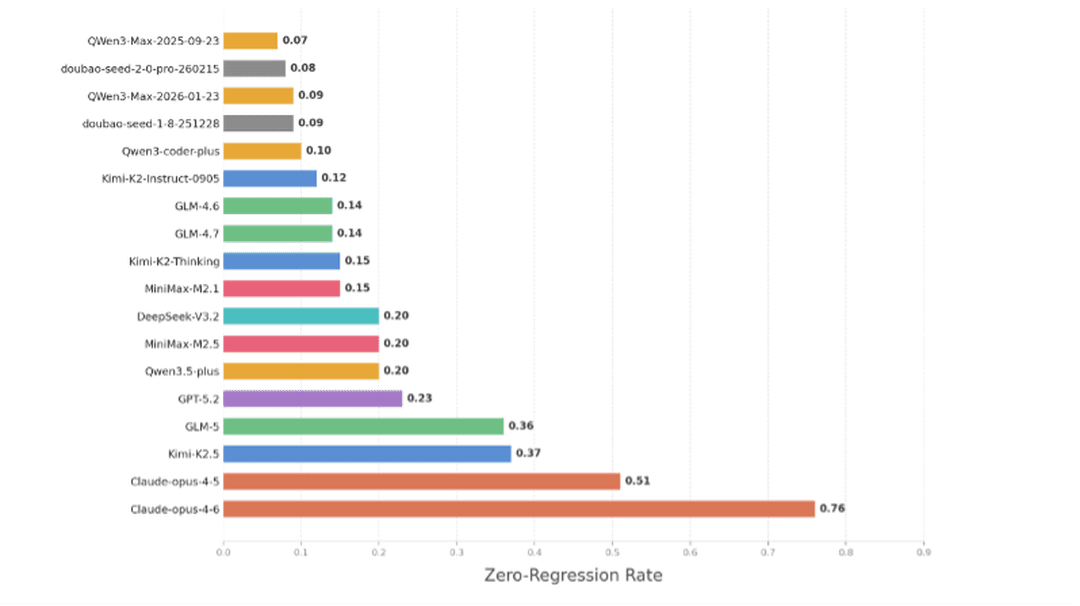
Plus intéressant encore, les chercheurs ont mesuré la capacité de chaque modèle à ne pas casser ce qui fonctionne déjà en ajoutant du nouveau code. Claude Opus 4.6 y parvient dans 76% des tâches, Claude Opus 4.5 dans 51%. Après, c'est la chute : Kimi-K2.5 et GLM-5 plafonnent à 37%, GPT-5.2 tombe à 23%, et la majorité des modèles restent sous les 20%. Autrement dit, pour la plupart des LLM du marché, le modèle casse du code fonctionnel en voulant en ajouter du nouveau dans plus de huit cas sur dix.
Garder un feedback humain, une nécessité
Très concrètement, ces résultats montrent que le fossé entre le meilleur modèle et le reste du peloton est considérable et pas seulement sur le score global. L'écart est surtout flagrant sur la capacité à ne pas dégrader l'existant, qui est au fond le nerf de la guerre. Les chercheurs notent aussi que les modèles post-2026 progressent nettement plus vite que leurs prédécesseurs, signe que les fournisseurs commencent à optimiser leurs modèles pour la maintenabilité du code et plus seulement pour sa justesse fonctionnelle immédiate.
Le comparatif reste toutefois incomplet, plusieurs modèles propriétaires n’ayant pas été testés (Codex, Gemini…). SWE-CI offre néanmoins un nouveau benchmark (dataset disponible sur Hugging Face) que chaque entreprise peut utiliser pour tester ses propres modèles sur la durée. Ces premiers résultats confirment aussi ce que la communauté développeur pressentait déjà : Claude Opus 4.6 se distingue nettement sur les tâches de maintenance de code. Pour autant, même le meilleur modèle ne garantit pas un sans-faute : l'IA peut encore casser du code dans certains cas. La supervision humaine reste, pour l'heure, un filet de sécurité plus que nécessaire.