
Comment fine-tuner en no code des modèles d'IA avec AutoTrain d'Hugging Face


Le no code est-il le futur du machine learning et de l'IA générative ? Si l'état du domaine est encore loin de se passer du développement, Hugging Face y contribue de manière significative en démocratisant l'accès aux modèles de langage via des interfaces simples et intuitives. En illustre la facilité d'utilisation d'AutoTrain, un outil maison pour fine-tuner des modèles rapidement et simplement. L'interface permet d'entraîner des modèles de pointe en traitement du langage naturel (NLP), vision par ordinateur (CV), reconnaissance vocale et même pour les tâches tabulaires. L'objectif est de faciliter l'entraînement, et pas seulement pour les data scientists ou ingénieurs ML.
Pour utiliser AutoTrain, deux options sont proposées : en no code depuis l'interface graphique directement sur le site d'Hugging Face (en créant un espace avec le modèle Docker AutoTrain) ou pour les développeurs via l'API Python ou en exécutant en local l'interface utilisateur AutoTrain Advanced. Nous présentons dans cet article la version no-code, accessible depuis https://huggingface.co/autotrain.
Créer un Space Hugging Face
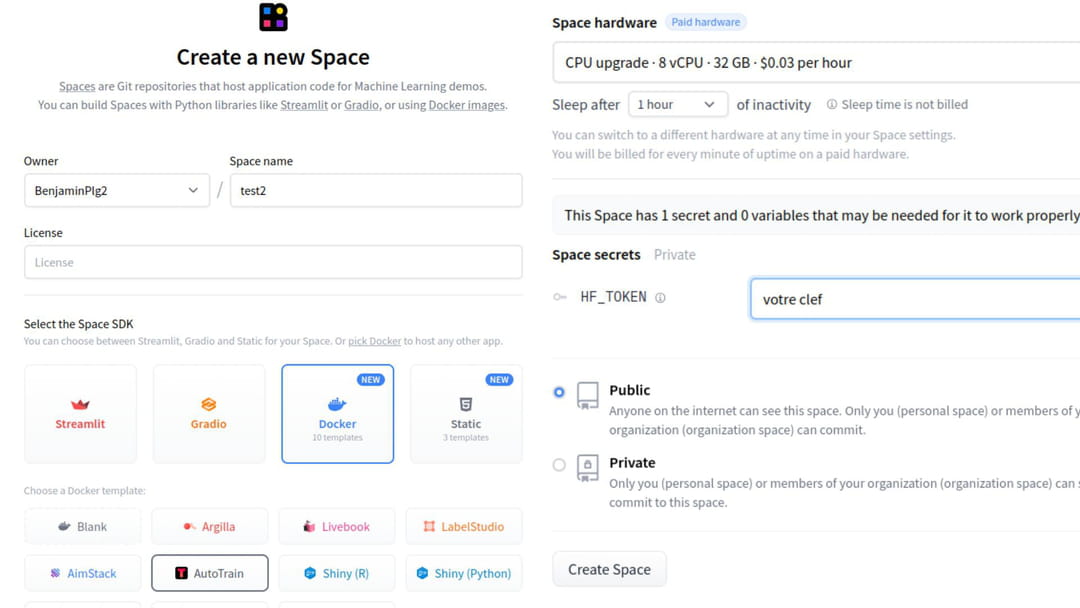
Pour débuter un nouveau projet AutoTrain, il est nécessaire de créer un "Space", un répertoire où sera déployé votre projet d'IA. Il faut ensuite définir un nom de projet, une licence d'utilisation (apache-2.0, OpenRAIL…), et sélectionner le kit de développement Docker avec le template "AutoTrain". L'interface exige enfin de choisir le type de ressource mis à disposition pour votre projet. Hugging Face propose plusieurs CPU et GPU, avec des prix compris entre 0 pour un simple CPU et 4,13 dollars de l'heure pour un GPU avec beaucoup de VRAM. Enfin, il est nécessaire d'entrer manuellement une clé d'API Hugging Face préalablement créée. Pour finir, il est possible de configurer la visibilité du projet, publique ou privée.
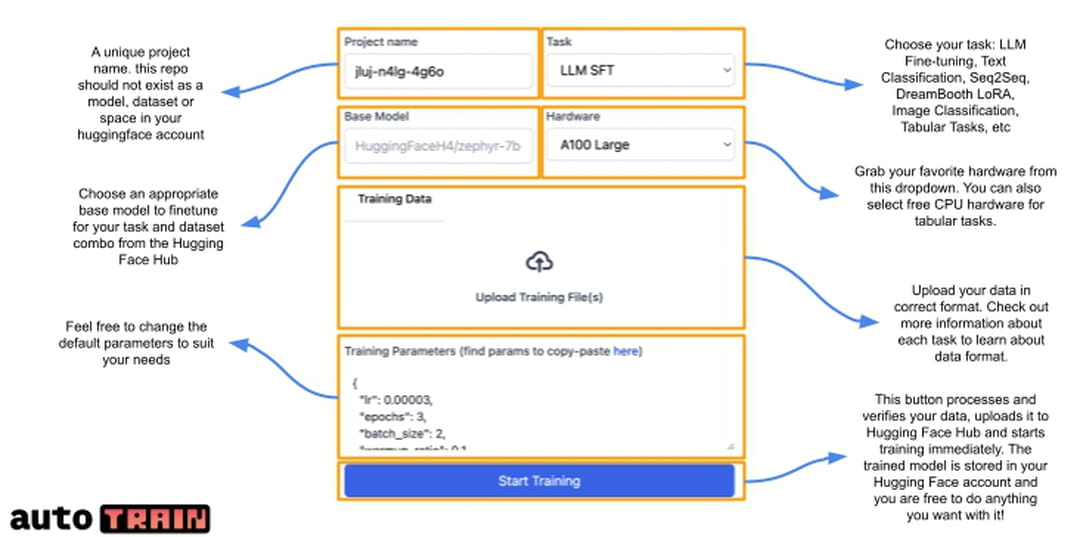
Une fois le Space créé, AutoTrain s'exécute. C'est depuis cette interface que l'ensemble des réglages préalables à l'entraînement des modèles doivent être renseignés. Après avoir défini le nom du projet, l'interface vous invite à sélectionner le type d'entraînement souhaité :
- LLM Finetuning : Ces tâches sont dédiées à l'ajustement fin des grands modèles de langage (LLM). Elles incluent :
- LLM SFT : Finetuning supervisé pour personnaliser le modèle sur des données spécifiques.
- LLM Generic : Tâches générales pour les LLM sans ajustement fin spécifique.
- LLM DPO : Optimisation de la distribution de la prédiction pour les LLM.
- LLM Reward : Utilisation de récompenses pour guider l'apprentissage du modèle.
- Other Text Tasks : Cette section comprend des tâches comme la classification de texte, où le modèle apprend à catégoriser les entrées textuelles, et la séquence à séquence, qui concerne la traduction ou le résumé de texte.
- Image Tasks : Ici, on trouve des applications telles que :
- DreamBooth LoRA : Une tâche récente qui utilise LoRA (Low-Rank Adaptation) pour la personnalisation de modèles génératifs.
- Image Classification : Classification d'images où le modèle attribue une étiquette à chaque image.
- Tabular Tasks : Dans cette catégorie, on s'intéresse à l'analyse de données tabulaires à travers :
- Tabular Classification : Classification basée sur des données structurées en tableaux.
- Tabular Regression : Régression pour prédire des valeurs continues à partir de données tabulaires.
Sélectionner un dataset
Une fois le type d'entraînement sélectionné, AutoTrain demande l'adresse du Space Hugging Face du modèle à fine-tuner. Exemple : mistralai/Mistral-7B-v0.1 pour le modèle Mistral 7B. Il est ensuite nécessaire de sélectionner le type de matériel à utiliser pour l'entraînement (comme lors de la création du Space). Enfin, cœur du réacteur, l'interface demande à ce que vous uploadiez le dataset qui servira à l'entraînement du modèle. Pour l'entraînement de modèles de classification de texte, les données doivent être fournies dans un fichier CSV avec deux colonnes texte et cible. Concernant l'entraînement par renforcement de grands modèles de langage, trois formats de fichiers CSV sont proposés selon la méthode choisie.
Pour la classification d'images, les photos doivent être rassemblées en dossier par classes dans une archive Zip sans autre contenu. Quant aux modèles de génération d'images, seules les images exemples du concept sont nécessaires. La traduction automatique requiert un fichier à deux colonnes texte source et texte cible. Enfin, la classification et régression de données tabulaires demande un fichier CSV avec au minimum des colonnes identifiant et valeur cible.
Un déploiement direct possible
Une fois les données téléversées au bon format sur la plateforme Hugging Face et les paramètres d'entraînement définis, l'utilisateur n'a plus qu'à cliquer sur le bouton "Lancer l'entraînement". AutoTrain se charge alors de préparer les données, de configurer automatiquement l'architecture et les hyperparamètres du modèle avant de procéder à l'entraînement à proprement parler.
L'interface permet de suivre la progression de la phase d'apprentissage. Une fois l'entraînement terminé, deux options s'offrent à l'utilisateur : directement déployer le modèle entraîné pour l'interroger en inférence, ou le télécharger pour l'utiliser sur son propre environnement. Dans les deux cas, il est très simple de passer des exemples au modèle pour obtenir des prédictions ou générer de nouveaux contenus.