
Gemma 7B vs Mistral 7B : Google se hisse à la hauteur du Français

La bataille de l'IA open source s'accélère encore. Alors que Mistral dominait le secteur des LLMs de taille moyenne depuis septembre 2023, Google frappe encore plus fort et repasse devant. La firme de Mountainview a dévoilé le 21 février une nouvelle famille de modèles open source : Gemma. Deux types de modèles sont publiés : Gemma 7B, optimisé pour l'inférence sur GPU et TPU (les puces maisons de Google) et Gemma 2B, développé spécialement pour être exécuté sur CPU, en local. Comme Mistral, Gemma arrive en deux versions : classique pour être fine-tuné par la suite et instruct pour une utilisation en mode conversationnel.
La famille Gemma est en réalité directement dérivée du modèle phare (mais propriétaire) de Google : Gemini. L'architecture, les données d'entraînement et les méthodes d'entraînement de Gemma sont similaires à celles utilisées pour Gemini. Contrairement aux modèles Gemini qui sont multimodaux (texte, image, vidéo, etc.), Gemma se concentre uniquement sur le texte. Cette version allégée et libre de Gemini vise à démontrer à la communauté open source que Google ne jette pas l'éponge et redouble d'efforts, tant dans l'intelligence artificielle propriétaire (avec l'annonce de Gemini 1.5 en février) que dans l'open source, et qu'il reste dans la compétition.
Filtrage des données pour Gemma
Bien qu'ils soient de la même taille (7 milliards de paramètres en sortie environ), Mistral 7B et Gemma n'ont pas été entraînés de la même manière. Google fournit beaucoup plus d'informations sur les données utilisées. On sait ainsi que Gemma 7B a été entraîné sur 6 billions (6 000 milliards) de tokens composés en majorité de documents issus du web, des mathématiques ou du code. Côté Mistral, on ne connait pas le nombre exact de tokens ni la nature des données utilisées pour l'entraînement du modèle. Pour l'architecture, Gemma se base, comme la majorité des modèles d'OpenAI, sur Transformer. L'équipe de Google y a cependant apporté plusieurs optimisations inspirées des dernières recherches en IA générative, notamment l'attention multi-requêtes (multi-query) qui accélère l'inférence, les embeddings positionnels rotatifs (RoPE) qui réduisent la taille des modèles ainsi que l'activation GeGLU qui améliore les performances globales. Ces choix permettent d'obtenir un modèle à la fois plus rapide, plus léger et plus efficace pour générer du texte de qualité.
Pour entraîner efficacement ses modèles sur des volumes massifs de données, Gemma utilise les TPU (Tensor Processing Units) de cinquième génération de Google qui sont adaptées au deep learning. Google a filtré au préalable le dataset global pour retirer les contenus CSAM (Child Sexual Abuse Material) et les éventuelles données personnelles comme les noms, email, numéros de téléphone… De son côté Mistral n'a évoqué aucun processus similaire. On sait en revanche que les modèles proposés par Mistral sont testés avant leur sortie par Giskard. Pour le fine-tuning post-entraînement, Mistral AI n'a pas communiqué davantage. Mistral 7B a été fine-tuné de manière assez classique sur des jeux d'instructions publiques. De son côté, Gemma a été fine-tuné de manière supervisée et par renforcement sur des données synthétiques et humaines, en anglais.
Gemma meilleur que Mistral en compréhension de texte
Gemma offre des performances globalement satisfaisantes sur une majorité de benchmarks. Au global, Gemma 7B surpasse Llama2 7B et 13B ainsi que Mistral 7B. Gemma excelle notamment dans le benchmark HellSwag indiquant une forte capacité à prédire la suite logique d'une histoire ou d'un scénario donné. De même, dans BoolQ, qui évalue la compréhension d'un texte, Gemma se distingue, encore. Mistral de son côté montre une supériorité notable dans le benchmark OpenBookQA, ce qui suggère une meilleure performance lorsqu'il est question de répondre à des questions de connaissance. Il se distingue également dans le benchmark "PIQA", indiquant une compétence supérieure en raisonnement physique intuitif.
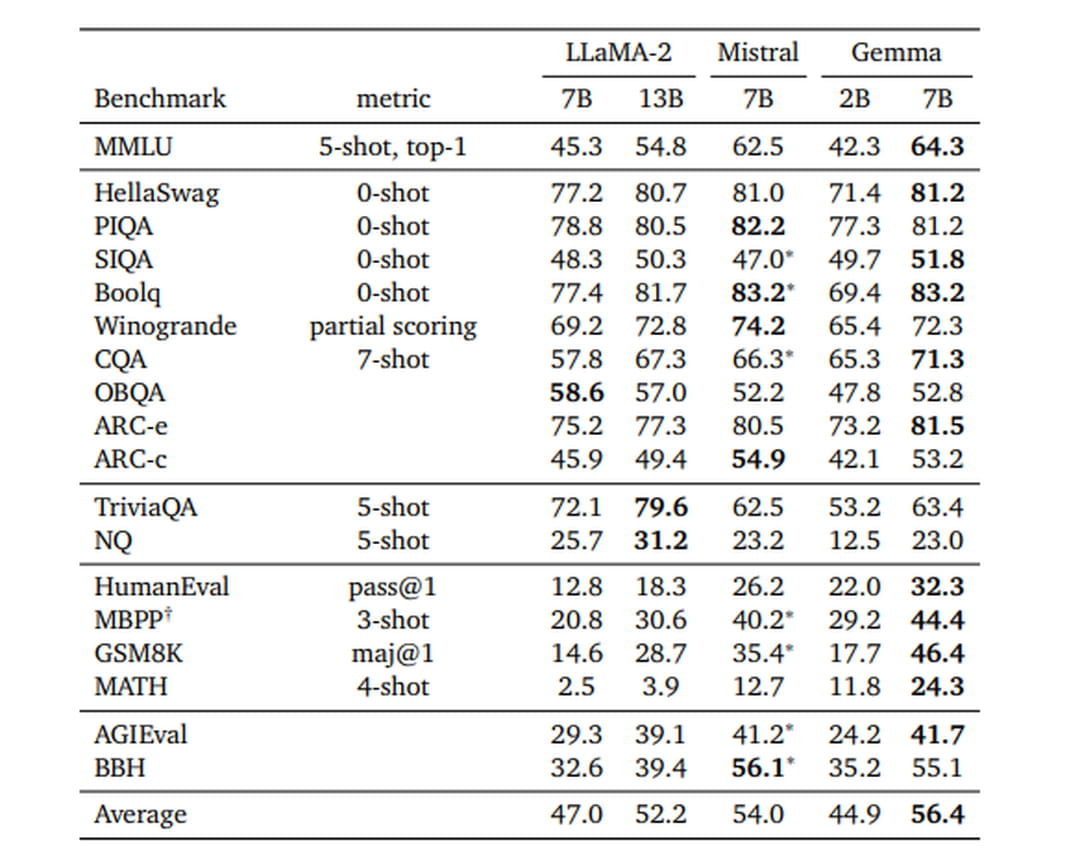
Mistral 7B est donc meilleur sur le raisonnement et les mathématiques mais Gemma l'emporte sur la génération de code. Les deux modèles font jeu égal sur de nombreuses tâches de compréhension du langage. Enfin, Llama 2 se distingue, encore et toujours, dans la compréhension de textes complexes et variés.
Un vocabulaire plus riche avec Gemma
En français et selon nos tests, Mistral et Gemma offrent des performances similaires dans la génération de texte. Le point revient cependant au petit dernier de Google qui offre un vocabulaire légèrement plus riche. Mistral offre un texte, souvent, plus pertinent. Pour rappel, les données d'entrainement étant composées de très peu de matériel français, les modèles de petites tailles offrent des performances beaucoup plus aléatoires lors de la génération de texte en français. En résumé de texte, Gemma se démarque et offre le meilleur résumé en reprenant les éléments clé. Mistral propose un résumé plus condensé qui oublie certains éléments importants.

En génération de code, Gemma et Mistral offrent tous deux de bonnes performances. Mistral 7B se démarque toutefois avec un code global plus propre et plus efficient. De manière générale et selon nos tests, le code est plus concis. Gemma offre toutefois une meilleure explicabilité du code et détaille avec précision comment l'exécuter proprement.

Le choix entre Gemma et Mistral dépendra grandement de l'usage que vous souhaitez en faire. Si vos besoins portent sur la compréhension poussée de textes, la génération de résumés ou des tâches de classes grammaticales, Gemma 7B semble plus adapté. En revanche, si vos cas d'usage nécessitent davantage de raisonnement logique, de traitement du langage mathématique ou de génération de code informatique, alors Mistral 7B répondra certainement mieux à ces exigences spécifiques.
De manière générale, Gemma offre une expérience utilisateur plus soignée, avec un effort de documentation et de transparence indéniable. Mistral mise davantage sur la rapidité d'exécution et les performances brutes, au détriment parfois d'aspects annexes comme la responsabilité. Avec Gemma, Google contribue à une saine concurrence dans l'IA open source et offre une solution technique performante de plus pour de nombreux usages.