
Tutoriel : entraînez votre propre chatbot sur une FAQ sans dépenser un centime


On le sait, le fine-tuning peut être coûteux. L’affinage des LLM permet de spécialiser un modèle pré-entraîné sur un jeu de données spécifique pour des tâches précises. Pour cela, le fine-tuning utilise des cartes graphiques, ou GPU, spécialisées et complexes. Les entreprises louent cette puissance de calcul à des fournisseurs comme AWS, Google Cloud Platform ou Microsoft Azure. La consommation électrique et le stockage des données représentent également un coût.
Heureusement, il est possible de fine-tuner gratuitement, en passant notamment par trois outils. D’abord, Google Colab, qui "prête" gratuitement une carte graphique, GPU T4. Une ressource partagée mais non garantie. Une session peut par exemple être interrompue.
Egalement, on peut charger un grand modèle comme Llama 3 sur le petit GPU de Colab. Cela est permis grâce à l'adaptation quantifiée de faible rang, ou QLoRA. Celui-ci combine LoRA, ou Low-Rank Adaptation, une technique utilisée pour adapter les modèles de machine learning à de nouveaux contextes, et la quantization, qui convertit les poids du modèle en nombres plus petits, de 32 bits à 4 bits, pour économiser la mémoire. Grâce à cela, QLoRA contribue à réduire l'empreinte mémoire du modèle, tout en conservant la précision pour l'entraînement.
Enfin, on peut se servir de la bibliothèque Unsloth. Elle réécrit des parties du code de bas niveau, celui qui dialogue directement avec le matériel. Pour cela, Unsloth change la manière dont la machine exécute le code python. Il remplace les instructions génériques par des recommandations sur mesure pour le matériel de Colab. Cela permet de gagner de la vitesse et d'économiser de la mémoire.
Tester librement le fine-tuning
Afin de mettre en place du fine-tuning gratuit, nous allons créer un assistant IA spécialisé dans les FAQ avec Google Collab. Notons que ce processus de fine-tuning n’est pas à confondre avec celui du RAG, pour retrieval augmented generation. Le fine-tuning ajuste durablement le modèle, tandis que le RAG l’enrichit de façon flexible avec des données externes. Si le fine-tuning requiert une formation intensive, lui permettant d’intégrer un manuel d’entreprise par exemple, avec la culture, le ton à adopter, le RAG ne modifie pas le modèle. Il récupère des informations dans une base de documents externe pour répondre.
Pour créer cette FAQ, nous allons travailler sur les données d’un site e-commerce fictif, "VeloCity". Le fait de mettre cela en place permettra d’expérimenter sans contraintes de confidentialité le fine-tuning. Cela permettra aussi de suivre les différentes étapes de sa mise en place. Cette expérimentation peut également permettre de valider la faisabilité technique et l'intérêt métier d'un assistant conversationnel spécialisé. Les techniques apprises sont d’ailleurs applicables à d'autres domaines (support technique, documentation interne, FAQ médicale…).
Pour faire fonctionner cela, nous avons besoin de quelques prérequis : un compte Google, Hugging Face et une autorisation au modèle Llama 3 de Meta. Pour cela, direction cette page. Nous cliquons sur "Agree" en bas. Notons qu’il faut accepter de partager nos coordonnées pour accéder à ce modèle. "Les informations que vous fournissez seront collectées, stockées, traitées et partagées conformément à la politique de confidentialité de Meta", écrit l’entreprise de Mark Zuckerberg. Celle-ci doit examiner la demande d’accès à ce dépôt avant d’accepter ou non votre requête.
Direction désormais notre atelier de travail, Google Colab. Nous appuyons sur le bouton bleu "Nouveau notebook". Pour activer l'accélérateur GPU, nous allons dans Exécution > Modifier le type d'exécution et GPU T4.
Nous allons désormais préparer un jeu de données pour l’assistant FAQ. C’est une étape importante, car la qualité de l’assistant dépend directement de la qualité des données. Les sources idéales sont la page FAQ existante, les tickets de support client, les emails ou chats avec les clients, la documentation de nos produits ou services. Nous générons cette FAQ au plus simple, pour un site e-commerce fictif, "VeloCity." Nous nous aidons notamment de l’IA pour mettre en place les différents éléments du code. Dans la section code, nous collons cela, et nous appuyons sur le bouton "Play" :
# === QUESTIONS ET RÉPONSES ===
# Remplacez le contenu ci-dessous par la FAQ de VOTRE site.
faq_de_mon_site = [
{
"question": "Quels sont les délais de livraison ?",
"reponse": "La livraison standard prend entre 3 et 5 jours ouvrés. Nous avons aussi une option express en 24h."
},
{
"question": "Comment puis-je retourner un article ?",
"reponse": "Vous avez 30 jours pour retourner un article. Il suffit de vous connecter à votre compte et d'imprimer une étiquette de retour gratuit."
},
{
"question": "Les vélos sont-ils livrés montés ?",
"reponse": "Nos vélos sont livrés presque entièrement montés. Il ne vous restera qu'à fixer les pédales et le guidon avec les outils fournis."
}
]
Nous installons ensuite Unsloth. Dans une nouvelle section Code dans Colab, nous écrivons :
# Installation "Unsloth" !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
On charge ensuite le modèle IA.
# Sélection du modèle IA from unsloth import FastLanguageModel import torch model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/llama-3-8b-Instruct-bnb-4bit", # Un modèle Llama 3 optimisé max_seq_length = 2048, load_in_4bit = True, )
Nous transformons maintenant notre FAQ brute en format compréhensible par le modèle d'IA
# On prépare les données
from datasets import Dataset
def formater_pour_ia(dataset):
conversations = []
for item in dataset:
conversations.append([
{"role": "system", "content": "Tu es un assistant expert du site VeloCity. Réponds clairement aux questions des clients."},
{"role": "user", "content": item["question"]},
{"role": "assistant", "content": item["reponse"]}
])
return {"messages": conversations}
formatted_data = formater_pour_ia(faq_de_mon_site)
dataset = Dataset.from_dict(formatted_data)
def apply_chat_template(examples):
return {"text": [tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False) for convo in examples["messages"]]}
dataset = dataset.map(apply_chat_template, batched=True)
Nous configurons et lançons l'entraînement du modèle sur notre FAQ.
# On dit à l'IA comment apprendre (avec la technique LoRA) model = FastLanguageModel.get_peft_model( model, r=16, lora_alpha=16, target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], lora_dropout=0, bias="none", ) # On lance l'entraînement from trl import SFTTrainer from transformers import TrainingArguments trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = dataset, dataset_text_field = "text", max_seq_length = 2048, packing = False, args = TrainingArguments(per_device_train_batch_size=2, gradient_accumulation_steps=4, warmup_steps=5, max_steps=60, learning_rate=2e-4, fp16=True, logging_steps=1, optim="adamw_8bit", output_dir="outputs"), ) trainer.train()
A cette étape, nous recevons ce message :
wandb: (1) Create a W&B account. wandb: (2) Use an existing W&B account. wandb: (3) Don't visualize my results.
Wandb est un outil qui permet de suivre visuellement l'entraînement de notre modèle d'IA. Nous répondons "3" pour ne pas les voir. Le tableau qui apparait dans la réponse montre l'évolution de l'apprentissage.

La "perte" ou "erreur" du modèle diminue ici. Cela signifie que le modèle apprend correctement.
Après ces différentes phases, il est désormais temps de voir les résultats. Le code suivant permet de tester notre modèle directement dans Google Colab, pour voir s'il répond convenablement. La question posée est définie dans la variable question_test.
# Préparez-vous à discuter
from transformers import TextStreamer
import transformers
FastLanguageModel.for_inference(model)
text_streamer = TextStreamer(tokenizer)
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer, streamer=text_streamer, max_new_tokens=512)
# Posez votre question ici
question_test = "Comment je fais pour renvoyer un produit ?"
# L'IA va vous répondre
conversation = [
{"role": "system", "content": "Tu es un assistant expert du site VeloCity. Réponds clairement aux questions des clients."},
{"role": "user", "content": question_test}
]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt)
Nous recevons notamment en message cet extrait :
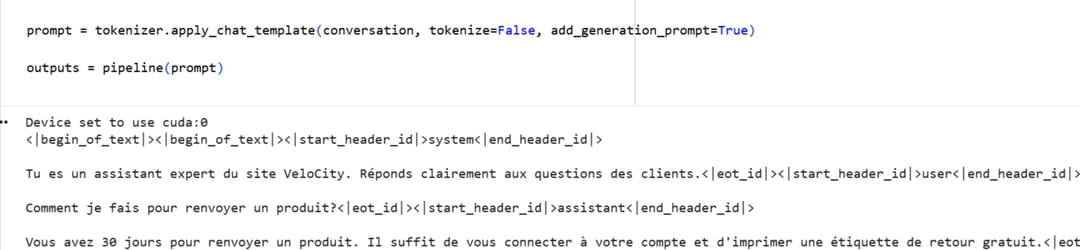
Nous voyons ici la sortie brute du modèle. Les balises comme <|assistant|> sont des tokens spéciaux que le modèle utilise pour structurer la conversation. A la question "Comment je fais pour renvoyer un produit ?", la réponse donnée est : "Vous avez 30 jours pour renvoyer un produit. Il suffit de vous connecter à votre compte et d'imprimer une étiquette de retour gratuit." Le fine-tuning a bien fonctionné. Le modèle est déjà entraîné et chargé en mémoire. Nous ne sommes plus en phase d'entraînement, mais en phase d'inférence, c'est-à-dire d'utilisation.
Pour poser facilement d'autres questions, dans la même cellule de code, il faut trouver la ligne qui définit la variable question_test et modifier l’interrogation. Puis d’exécuter à nouveau cette cellule en cliquant sur le bouton Play à sa gauche.
Création d’une interface de chat dans Google Colab
Nous allons maintenant créer une interface de chat directement dans Colab. Pour cela, nous allons utiliser une bibliothèque appelée ipywidgets. Elle permet de créer des éléments interactifs (boutons, zones de texte, curseurs...) directement dans Google Colab. Nous copions-collons tout le bloc de code suivant dans une nouvelle cellule de code à la fin de Colab.
Python
# --- Étape 1 : Import des outils nécessaires --- import ipywidgets as widgets from IPython.display import display import threading import time # --- Étape 2 : Création des éléments de l'interface --- # La grande zone où s'affichera la conversation chat_history = widgets.Textarea( value="???? Bonjour ! Je suis l'assistant VeloCity. Posez-moi votre question.", placeholder='La conversation apparaîtra ici...', layout=widgets.Layout(width='100%', height='300px'), disabled=True # On ne peut pas écrire directement dedans ) # La petite zone où vous écrivez votre question user_input = widgets.Text( placeholder='Tapez votre question ici et appuyez sur Entrée...', layout=widgets.Layout(width='100%') ) # Le bouton "Envoyer" (même si on utilisera surtout la touche Entrée) send_button = widgets.Button( description='Envoyer', button_style='success', # 'success', 'info', 'warning', 'danger' or '' layout=widgets.Layout(width='100%') ) # --- Étape 3 : La logique de la conversation --- # On garde en mémoire l'historique de la conversation pour l'IA conversation_history_for_ia = [ {"role": "system", "content": "Tu es un assistant expert du site VeloCity. Réponds clairement aux questions des clients."}, ] def get_bot_response(question): """Fonction qui envoie la question à l'IA et récupère la réponse.""" global conversation_history_for_ia # On ajoute la question de l'utilisateur à l'historique de l'IA conversation_history_for_ia.append({"role": "user", "content": question}) # On prépare le prompt pour le modèle prompt = tokenizer.apply_chat_template(conversation_history_for_ia, tokenize=False, add_generation_prompt=True) # On demande à l'IA de générer la réponse outputs = pipeline(prompt) # On extrait la réponse de l'IA # La réponse est dans outputs[0]['generated_text'] après la dernière balise assistant raw_answer = outputs[0]['generated_text'] answer = raw_answer.split('<|start_header_id|>assistant<|end_header_id|>')[-1].strip() # On ajoute la réponse de l'IA à son historique pour qu'elle s'en souvienne conversation_history_for_ia.append({"role": "assistant", "content": answer}) return answer def on_submit(sender): """Fonction appelée quand on appuie sur Entrée ou sur le bouton.""" user_question = user_input.value if not user_question: return # Affiche la question de l'utilisateur dans le chat chat_history.value += f'\n\n???? Vous : {user_question}' user_input.value = '' # On vide la zone de saisie # Affiche un message "en train d'écrire..." chat_history.value += '\n\n???? L\'IA réfléchit...' # On lance la récupération de la réponse dans un thread pour ne pas bloquer l'interface def get_response_thread(): bot_answer = get_bot_response(user_question) # On met à jour l'interface depuis le thread principal chat_history.value = chat_history.value.replace('???? L\'IA réfléchit...', f'???? Assistant : {bot_answer}') thread = threading.Thread(target=get_response_thread) thread.start() # On lie la fonction on_submit à l'appui sur Entrée et au clic sur le bouton user_input.on_submit(on_submit) send_button.on_click(on_submit) # --- Étape 4 : Affichage de l'interface de chat --- # On organise les éléments verticalement chat_interface = widgets.VBox([chat_history, user_input, send_button]) # On affiche l'interface display(chat_interface)
Nous exécutons cette cellule en cliquant sur le bouton Play. Une jolie fenêtre de chat va apparaître directement sous la cellule.

Tester pour mieux appréhender l’outil
L’intérêt de ce fine-tuning de FAQ sur Colab est de valider plusieurs aspects. Vous vérifiez que l'IA peut assimiler votre vocabulaire spécifique et répondre de manière cohérente. Vous pouvez comparer les réponses du modèle fine-tuné avec celles d'un modèle générique. Si le modèle fine-tuné donne des réponses plus précises et adaptées, c'est bon signe. Vous pouvez aussi découvrir le temps d'entraînement ou la taille des données nécessaires. Le chatbot peut également être utilisé par des collègues et clients tests. Recueillir leurs retours pourra permettre de décider de développer ou non la solution complète.