
Comparatif : les meilleures plateformes d'observabilité pour l'IA générative


Un certain nombre de projets LLM échouent à la phase de maintien en production. La raison peut être l'incapacité à mesurer objectivement la qualité du système et à diagnostiquer les régressions. La difficulté d’un pipeline LLM est qu’il produit des réponses probabilistes, dont la qualité dépend de nombreuses variables. On peut citer la pertinence des chunks récupérés, la densité informationnelle du contexte injecté dans le prompt, la température du modèle, la longueur de la fenêtre de contexte, et les interactions entre toutes ces dimensions.
Plutôt que d’estimer la qualité du projet LLM au seul ressenti, on peut passer par une plateforme d’observabilité. Celle-ci permet de surveiller, comprendre et résoudre les problèmes des systèmes IA tout au long de leur cycle de vie. Sa maîtrise permet de traiter un pipeline LLM de façon plus rigoureuse.
Trois solutions comparées
Sur ce marché de l’observabilité en plein essor, cohabitent les outils conçus pour les LLM, comme LangSmith et Arize Phoenix, des plateformes MLOps pour "Machine Learning Operations", qui ont étendu leur périmètre, et des outils de monitoring ayant ajouté une couche IA, comme Datadog LLM Observability. Nous avons choisi de comparer les trois nommés. Ils représentent chacun une approche spécifique. Afin de mieux comprendre leur philosophie, l’installation, le fonctionnement et l’intérêt de ces plateformes, nous appliquons l’observabilité à un chabot personnalisé avec du RAG. Il a été préalablement construit, pour un précédent papier.
|
Critère |
LangSmith |
Datadog LLM Observability |
Arize Phoenix |
|
Philosophie |
Voir à l'intérieur du pipeline |
Voir autour du pipeline |
Mesurer la qualité des réponses |
|
Modèle |
SaaS commercial |
SaaS commercial |
Open source |
|
Plan gratuit |
Oui |
Oui |
Oui |
|
Traçage des appels LLM |
Oui |
Oui |
Oui |
|
Suivi latence & coûts |
Oui |
Oui |
Oui |
|
Surveillance infrastructure |
Non |
Oui |
Non |
|
Détection prompt injection |
Non |
Oui |
Non |
|
Métriques qualité RAG |
Partiel |
Non |
Oui |
|
Visualisation des embeddings |
Non |
Non |
Oui (UMAP 2D/3D) |
|
Intégration LangChain native |
Oui (native) |
Via agent |
Via instrumentation |
|
Profil idéal |
Développeur |
Équipe Ops/Production |
Spécialiste IA/ML |
|
Quand l'utiliser ? |
Développement et débogage |
Exploitation en production |
Évaluation de la qualité |
LangSmith : comprendre son RAG en un coup d’œil
Développé par LangChain Inc., LangSmith se positionne comme une plateforme de débogage, d'évaluation et de monitoring pour les applications LLM. Il permet de comprendre ce qui se passe à l’intérieur des pipelines LLM créés une fois lancés. Pour cela, il affiche des métriques clés comme la latence, le taux de succès des prédictions et l'utilisation des ressources. Il est possible de démarrer gratuitement.
Son installation nécessite une clef API.
Nous tapons dans Powershell :
$env:LANGCHAIN_TRACING_V2 = "true" $env:LANGCHAIN_API_KEY = "votre_cle_langsmith" $env:OPENAI_API_KEY = "votre_cle_openai"
Puis, nous relançons le chatbot en tapant : python app.py
Les traces, c'est-à-dire les enregistrements par appel reçu par celui-ci, apparaissent dans notre compte LangSmith.

Le tableau affiché est sobre. Il montre les indicateurs liés à ChatOpenAI, le LLM que nous avons sélectionné, et VectorStoreRetriever, le composant chargé de chercher les documents pertinents dans la base vectorielle avant de les transmettre au LLM. Sont analysés l’input, l’output, d’éventuels messages d’erreurs, le temps de latence, ou le nombre de tokens. Cela permet d’en savoir rapidement plus sur le comportement du chatbot RAG. On voit par exemple que 196 tokens ont été consommés pour un appel. C'est ce qui est facturé par OpenAI. Au niveau des performances, la latence, en rouge (0,80 s) sur le LLM est un peu élevée. Si elle dépasse 3 à 4 secondes régulièrement, cela peut indiquer un problème de charge ou un prompt trop long. Avec ce rapport, vous pouvez aussi enrichir votre base de données en fonction des requêtes récurrentes des utilisateurs.
Nous entrons plus dans le détail en cliquant sur "ChatOpenAI." Cette fenêtre apparait.
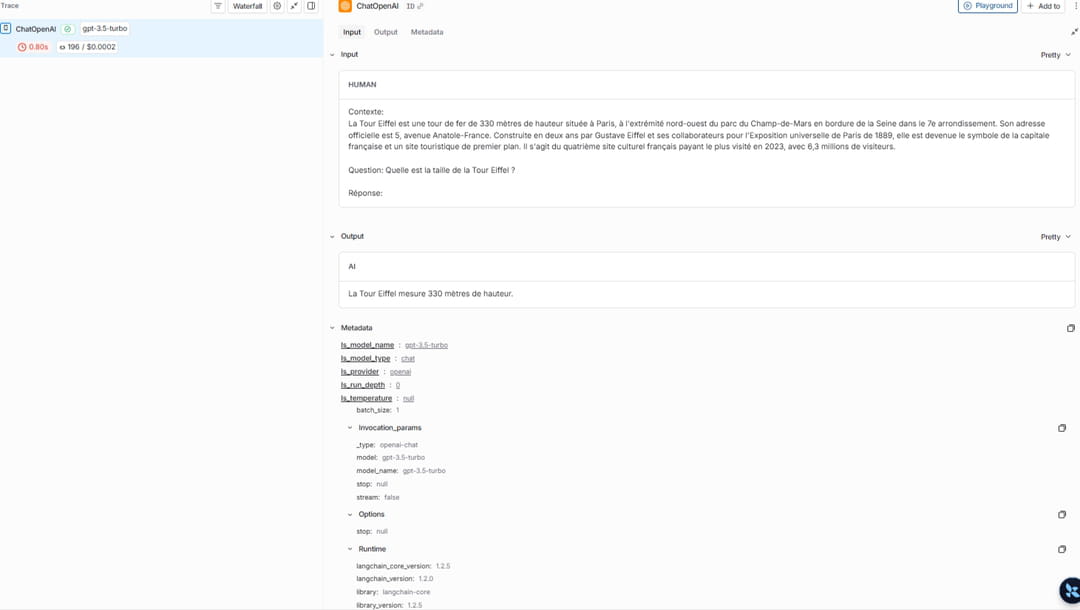
Elle permet là aussi de rapidement observer les erreurs éventuelles et de mieux appréhender à quelle étape du processus il y a eu un souci. Nous observons par exemple que le texte préalablement renseigné dans le chabot a bien été pris en compte. Le LLM a lu le contexte fourni et en a extrait la réponse. Il est aussi possible de prendre connaissance de paramètres comme la Température, via la section Metadata située en dessous.
Datadog LLM Observability multiplie les points de rupture potentiels
Datadog est une plateforme SaaS d’observabilité et de sécurité pour les applications cloud. Elle permet de visualiser ses modèles au sein de la même plateforme que son infrastructure (AWS/Azure), ses logs et ses bases de données. Elle offre pour cela différents indicateurs clés, autour des performances et des coûts, de la qualité et de la sécurité.
Son installation nécessite une clef API. Elle se trouve sur app.datadoghq.eu. Pour y accéder, il faut cliquer sur le profil puis dans Organization Settings, en bas à gauche. Il faut aussi mettre en place ddtrace, qui intercepte les appels OpenAI et les envoie à Datadog.
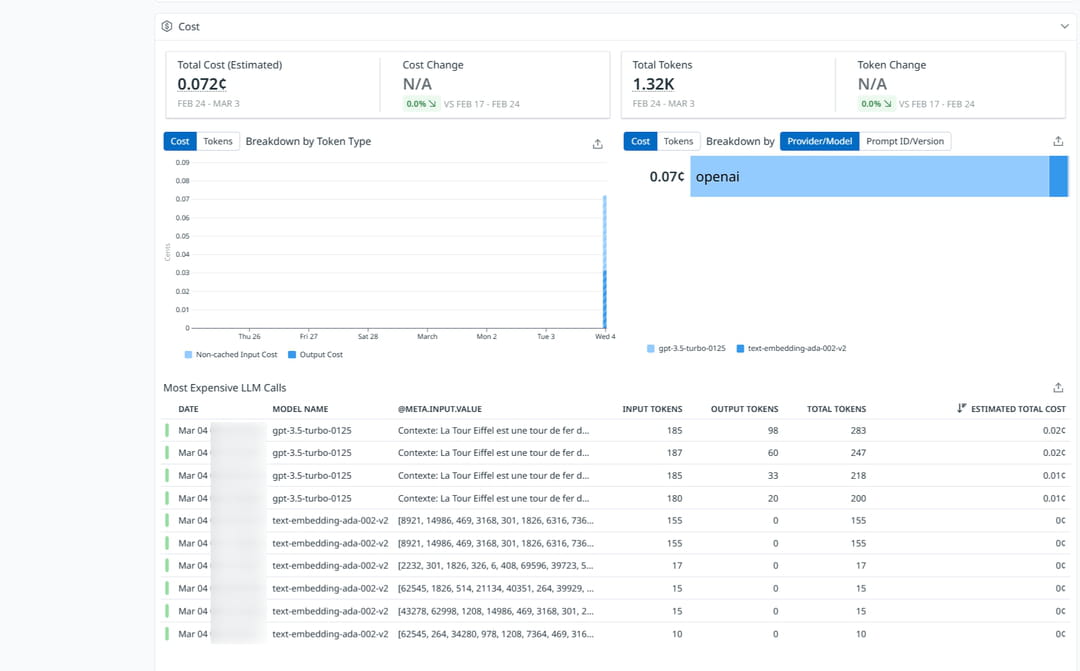
L’interface est sobre. Le tableau de bord doit permettre d’anticiper certains problèmes grâce à des données précises. Datadog LLM Observability affiche par exemple le pourcentage d’appels LLM qui ont échoué. Un taux élevé signale un problème d'API, de quota ou de configuration. Un suivi financier permet de connaître les requêtes anormalement coûteuses. La section "Latency" présente la courbe de la latence dans le temps et liste les opérations les plus lentes. On peut par exemple observer que la création des embeddings est en réalité plus lente que la génération de réponse. C'est une information non intuitive que seule l'observabilité révèle. Cela pourrait orienter une optimisation vers la mise en cache des embeddings.
Arize Phoenix : des métriques prédéfinies
Phoenix d'Arize AI est une plateforme open source censée donner un contrôle complet sur l'évaluation des LLM. Elle permet de mieux comprendre les différentes étapes de fonctionnement du chatbot et les erreurs possibles rencontrées. Elle travaille avec des évaluateurs prédéfinis pour des tâches courantes comme le RAG. La plateforme est particulièrement pertinente en phase d'évaluation avant déploiement, en contexte de données sensibles et quand la qualité des réponses est critique. On peut commencer par un plan gratuit (https://phoenix.arize.com/pricing/)
Sa mise en place est relativement aisée. Elle requiert l’installation de Phoenix et les dépendances d’instrumentation dans Powershell.
pip install arize-phoenix pip install openinference-instrumentation-langchain pip install openinference-instrumentation-openai pip install opentelemetry-sdk pip install opentelemetry-exporter-otlp
Nous désactivons LangSmith et Datadog pour éviter les conflits :
$env:LANGCHAIN_TRACING_V2 = "false" $env:DD_LLMOBS_ENABLED = "0"
Dans un premier terminal PowerShell, nous lançons Phoenix :
cd C:\chatbot-rag-local .\venv\Scripts\Activate.ps1 python -m phoenix.server.main serve
Nous ouvrons le fichier app.py, préalablement construit, et ajoutons ces lignes tout en haut, avant tous les autres imports :
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# Connecte l'application à Phoenix
tracer_provider = register(
project_,
endpoint="http://localhost:6006/v1/traces"
)
# Instrumente automatiquement LangChain
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
Nous ouvrons un deuxième terminal PowerShell :
cd C:\chatbot-rag-local .\venv\Scripts\Activate.ps1 python app.py
Nous ouvrons notre chatbot et posons quelques questions. Puis, nous allons sur Phoenix sur http://localhost:6006.
Nous cliquons sur le projet "chatbot-jdn-rag" dans la liste. On voit que les indicateurs sont fournis et détaillés. Les traces apparaissent avec les métriques de qualité RAG.

Par exemple, la colonne "Annotations" affiche les scores de qualité RAG (fidélité, pertinence du contexte, taux d'hallucination), une fois configurés les évaluateurs automatiques.
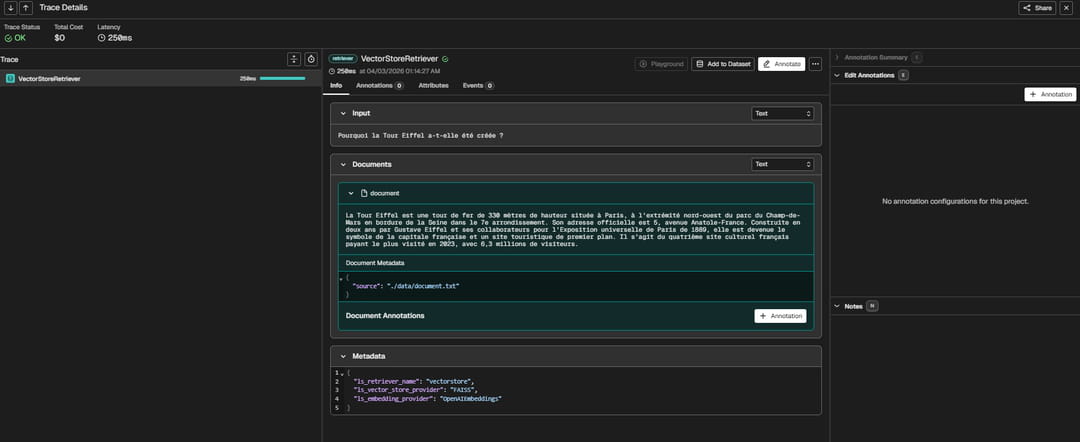
En cliquant sur « VectorStoreRetriever », on comprend davantage le fonctionnement du chatbot. Ici, notre question portait sur les motivations de la création de la Tour Eiffel. Le chunk retourné mentionne bien l'Exposition universelle de 1889 comme contexte de construction. Cependant, le chunk ne développe pas les raisons profondes de sa création. C'est le type d'analyse que Phoenix permet : juger visuellement si le document récupéré était le bon pour répondre à la question. Cet affichage permet aussi de diagnostiquer les hallucinations à la source.
Phoenix permet de aussi visualiser les embeddings en 2D ou 3D. Cela permet de voir concrètement si les chunks sont bien regroupés par thématique, si certains documents sont isolés et donc peu susceptibles d'être récupérés, ou si des questions utilisateurs tombent dans des zones vides de votre base.
Limites des plateformes d’observabilité pour l’IA générative
Notons que le marché des plateformes d’observabilité pour l’IA générative reste fragmenté et manque de standards unifiés. Parallèlement, les exigences croissantes en matière de gouvernance, de conformité réglementaire et d'éthique exigent une transparence que certaines plateformes actuelles peinent à fournir.