
Comment le JDN a conçu et déployé un chatbot RAG avec AgentKit d'OpenAI


Et si concevoir un chatbot d’IA générative devenait accessible à tous ? C'était la promesse d'OpenAI avec le lancement d'AgentKit en octobre 2025. Ce SDK permet de créer des systèmes d'IA avec un minimum de code grâce à plusieurs modules complémentaires. Parmi eux, Agent Builder offre un canevas visuel pour concevoir des workflows multi-étapes, tandis que ChatKit propose des chatbots facilement intégrables sur une page web. Séduits par l'idée d'utiliser cet outil pour guider nos lecteurs dans le choix d'un modèle d'IA générative à partir de notre comparateur recensant (pour l'heure) plus de 155 modèles, nous avons tenté l'expérience.
Le principe de ChatKit
ChatKit repose sur une architecture en trois étapes. D'abord, on conçoit un workflow agentique via Agent Builder, l'interface visuelle d'OpenAI qui permet de configurer la logique métier du chatbot sur le principe de N8N. Ensuite, on configure un serveur backend qui crée des sessions ChatKit et échange des tokens d'authentification avec l'API OpenAI. Enfin, on intègre le widget de chat sur son site web via quelques lignes de JavaScript et React. L'ensemble permet de déployer un chatbot conversationnel sans avoir à développer l'interface utilisateur de A à Z, OpenAI gérant l'hébergement et la scalabilité du backend.
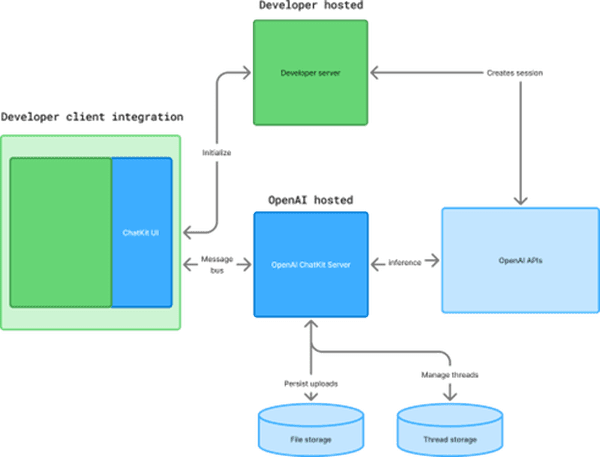
Sur le papier, l'architecture semble limpide : le widget de chat côté client dialogue avec les serveurs ChatKit d'OpenAI qui gèrent l'inférence, le stockage des fichiers et l'historique des conversations. Entre les deux, un serveur intermédiaire sécurise les échanges en créant les sessions et en gérant l'authentification.
#1 Création du workflow dans AgentBuilder
Pour créer notre chatbot interactif, nous commençons par concevoir le workflow de l'agent dans Agent Builder. Le cahier des charges est relativement simple sur le papier : développer un chatbot capable de conseiller les lecteurs du JDN sur le meilleur modèle adapté à leur besoin et leur projet spécifique, en prenant pour référence notre base de données des modèles. Celle-ci comprend les paramètres suivants : nom, modalité d'entrée, modalité de sortie, coût (estimé sur une échelle de ???? à ????????????), nature open source ou propriétaire, possibilité de fine-tuning, et scores sur les benchmarks que nous jugeons déterminants (MMLU, LiveCodeBench, SWE Bench Verified, AIME 2025). Le chatbot attribue ainsi le modèle le plus adapté au cas d'usage formulé par l'utilisateur.
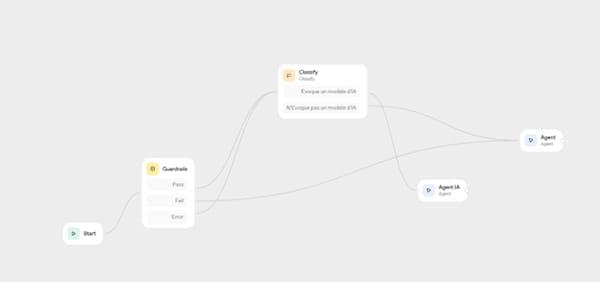
Agent Builder fonctionne avec des modules. Nous commençons par ajouter un module Guardrails qui permet de filtrer les requêtes des utilisateurs : modération des propos, réduction du risque de jailbreak, détection des textes NSFW et blocage des prompt injections, notamment. Une fois les guardrails passés, trois issues sont possibles : soit la requête est validée, soit elle échoue, soit une erreur se produit. Dans les deux derniers cas, nous demandons au chatbot de répondre à l'utilisateur qu'il ne peut pas traiter cette demande. Lorsque les guardrails sont franchis avec succès, la requête entre dans un module de classification (Classify) qui détermine si la question de l'utilisateur porte sur un modèle d'IA. Si c'est le cas, elle est dirigée vers l'agent IA principal, équipé du RAG et de notre base de données, pour formuler une recommandation adaptée. Dans le cas contraire, on informe poliment l'utilisateur que le chatbot est dédié au conseil sur les modèles d'IA et l'invite à reformuler sa question.
RAG ou données dans le prompt system ?
Pour la logique de l'agent IA, nous nous sommes interrogés sur l'usage du RAG ou l'ajout direct des données du tableau du guide des modèles dans le prompt système. Les deux méthodes ont leurs avantages et leurs inconvénients. Injecter les données du tableau dans le prompt est l'approche la plus simple. En revanche, cette méthode montre rapidement ses limites dès que le volume de données augmente : coûts et latence plus élevés, maintenance plus complexe lors des mises à jour du guide, et surtout un risque accru de réponses imprécises lorsque le modèle doit raisonner sur plusieurs centaines de lignes simultanément. Cette approche aurait toutefois pu voir son coût partiellement réduit grâce au mécanisme de prompt caching, qui permet de mutualiser le traitement d'un prompt système identique sur plusieurs requêtes, sans pour autant résoudre les limites de fiabilité.
Le RAG ajoute une légère complexité, mais tout à fait gérable : il faut vectoriser notre tableau et ajouter le module complémentaire dans Agent Builder. Pour chaque mise à jour, il faut revectoriser le fichier avec les données actualisées. Le jeu en vaut la chandelle pour maximiser l'efficacité du modèle. Nous choisissons donc d'opter pour une approche RAG. Pour ce faire, nous nous rendons dans l'outil de stockage des vecteurs d'OpenAI, le Vector Store. Pour l'heure, l'outil ne permet pas de vectoriser des données tabulaires au format CSV ou XLSX (Excel) : il gère uniquement les fichiers texte non structurés. Nous choisissons alors de convertir notre tableau en JSON (avec un prompt et Claude) pour obtenir un fichier .txt rempli de JSON. Nous avons opté pour le format JSON car il permet de conserver une structure explicite et lisible des champs du tableau (modèle, prix, modalités, etc.) tout en restant compatible avec la vectorisation de fichiers texte non structurés.
De retour dans Agent Builder, nous créons un module agent IA qui permet au modèle de répondre à partir de la requête utilisateur. Nous lui donnons en outil le File Search en renseignant l'ID du vecteur précédemment créé. Le modèle répondra alors en utilisant les données du fichier du guide des modèles.
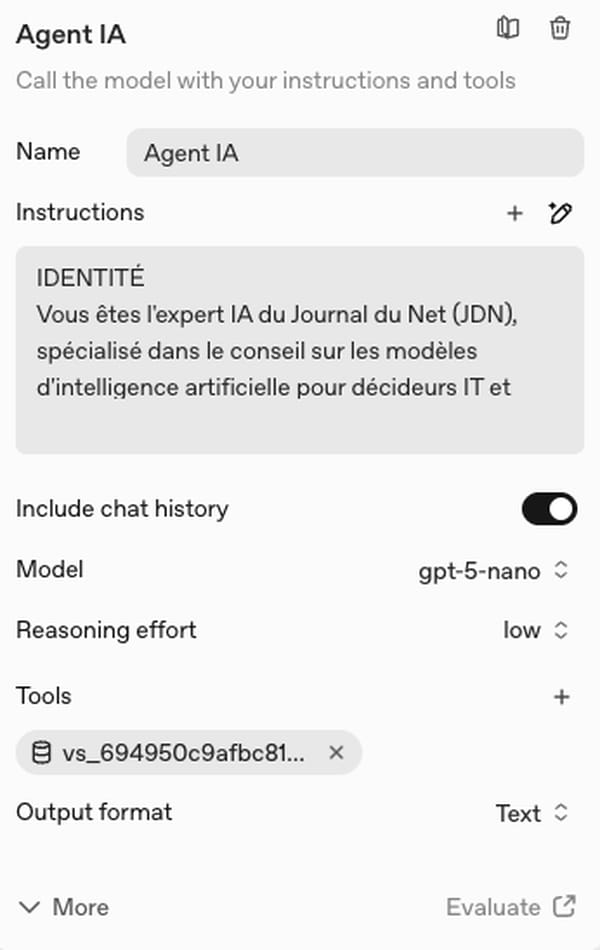
Choix du modèle
Pour le choix du modèle, nous décidons de nous tourner vers GPT-5.3-nano plutôt que GPT-4o pour des raisons de coût et de scalabilité future. Le modèle est l'un des moins chers et il devrait être supporté encore quelques mois par OpenAI. Il dispose d'un raisonnement minimal qui lui permettra, si par la suite nous le souhaitons, d'utiliser la recherche web assez efficacement pour répondre à la demande de l'utilisateur avec plus de précision (en donnant les articles du JDN en source par exemple). Nous choisissons d'activer le niveau de raisonnement "low", le minimum pour utiliser le RAG avec ce modèle.
Prompt
Le prompt est élaboré en prenant une base rédigée à la main, puis améliorée par Claude pour un meilleur formatage. Le prompt définit précisément l'identité éditoriale de l'agent, sa mission de conseil, son périmètre d'expertise, ses règles de style conversationnel, ainsi que la méthodologie à suivre pour qualifier un besoin avant toute recommandation. A noter que lors de nos différentes itérations, chaque micro-changement dans le prompt a eu une incidence sur l'ensemble des instructions. Il faut benchmarker et recommencer les tests à chaque nouvelle version.
Structure de notre prompt :
[IDENTITÉ] - Rôle/expertise - Ton & posture - Style conversationnel [MISSION] - Objectif principal - Valeur ajoutée différenciante [PÉRIMÈTRE] - Autorisations (scope) - Refus/limites - Règles de confidentialité [RÈGLES DE STYLE] - Format obligatoire (prose/liste/autre) - Interdictions formelles - Limite de tokens/mots [UTILISATION DES DONNÉES] - Sources (RAG/web/internal) - Notation spécifique (étoiles, scores) - Vérification obligatoire [RÈGLE FONDAMENTALE] - Workflow critique (ex: questions avant reco) - Exceptions au workflow [APPROCHE CONVERSATIONNELLE] - Logique d'adaptation (vague→précis) - Sujets à explorer - Nombre de questions/interactions [MÉTHODOLOGIE] - Hiérarchie de décision (critères ordonnés) - Logique de tranchage - Format de présentation résultats [SUIVI] - Proposition après action principale [EXEMPLES] - Mauvais vs Bon (2-3 cas concrets) [CAS LIMITES] - Données manquantes - Tentatives d'extraction
Pour des raisons de sécurité, nous ne pouvons diffuser la version actuelle du prompt en production.
#2 Personnaliser l’apparence du chatbot
Une fois la logique métier du bot configurée dans Agent Builder, il est temps de personnaliser l'apparence de notre chatbot. OpenAI propose une interface très simple d'utilisation dans son playground de ChatKit. Il est possible de configurer le thème en mode nuit ou jour, la couleur générale du bouton d'envoi, la police et la taille de police utilisées, la phrase d'accroche principale, les phrases de démarrage (les exemples), la possibilité d'uploader ou non des fichiers, et bien d'autres paramètres.
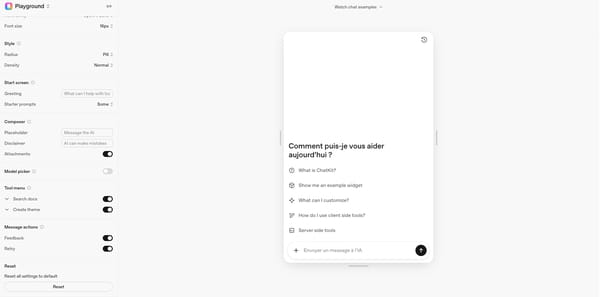
Les caractéristiques graphiques validées, il suffit de récupérer le code en cliquant sur la balise de code. L'ensemble de l'interface est donc pré-paramétré dans le code. Le GUI et la logique métier sont désormais configurés, nous pensons ensuite au déploiement, partie la plus technique pour les non-initiés.
#3 Le déploiement sur serveur de développement
Comme expliqué précédemment, le SDK ChatKit d'OpenAI ne peut pas fonctionner uniquement dans le navigateur. La raison est simple : votre clé API OpenAI, celle qui est liée à votre facturation, ne doit jamais se retrouver dans le code côté client. Dans le cas contraire, n'importe quel utilisateur un peu curieux pourrait ouvrir les outils développeur de son navigateur, récupérer cette clé et l'utiliser à vos frais. Pour éviter cela, OpenAI impose un mécanisme de sécurité : vous devez disposer d'un serveur intermédiaire qui détient votre clé API et qui, à chaque nouvelle conversation, contacte OpenAI pour créer une session. OpenAI renvoie alors un token temporaire, valable uniquement pour cet échange, que le serveur transmet au navigateur. Le widget ChatKit utilise ce token éphémère pour fonctionner, et votre clé API principale ne circule jamais côté client.
Pour mettre en place cette architecture, nous avons commandé un serveur VPS chez OVH, premier prix, quelques euros par mois suffisent amplement. Une fois la machine installée et sécurisée, nous avons déployé un backend minimaliste en Python avec FastAPI, un framework pour avoir une API en local. Notre serveur ne fait que deux choses : créer les sessions ChatKit en appelant l'API OpenAI, et servir la page HTML contenant le widget. Dans le script Python, nous avons intégré l'ID du workflow généré dans Agent Builder pour que chaque session pointe vers la logique métier de notre chatbot. Côté frontend, nous avons collé le code récupéré depuis le playground ChatKit, qui contient tous les paramètres d'interface configurés : thème, couleurs, police et phrases d'accroche.
Pour garantir que l'application tourne en permanence sans interruption, nous utilisons PM2, un gestionnaire de processus, tandis que Nginx joue le rôle de reverse proxy en recevant les requêtes HTTPS depuis Internet pour les rediriger vers notre application.
Le serveur FastAPI démarré et l'ensemble de la configuration mise en place, le widget de notre chatbot est exposé sur notre serveur web. Il suffit alors sur le JDN de créer un iframe pour l'héberger. Ainsi, lorsqu'un utilisateur se connecte sur la page contenant le widget, le navigateur de notre lecteur récupère le code du widget sur le VPS.
Pour la mise en production définitive, nous avons finalement fait le choix de dockeriser l'ensemble de l'application et de la migrer sur un serveur interne au groupe CCM Benchmark, éditeur du JDN. Si le VPS OVH a rempli son rôle durant la phase de développement et de tests, le passage en production imposait de s'aligner sur les standards d'infrastructure du groupe, tant pour des raisons de cohérence IT que de sécurité.
La containerisation via Docker nous permet de packager le backend FastAPI et sa configuration dans une image reproductible, facilitant les mises à jour et les éventuels rollbacks. Le fonctionnement reste strictement identique côté utilisateur : l'iframe pointe désormais vers notre infrastructure interne plutôt que vers le VPS externe, de manière totalement transparente.
Un chatbot fonctionnel en quelques jours
Au-delà de la configuration de base, nous avons implémenté plusieurs mécanismes de sécurité complémentaires pour éviter les abus et maîtriser les coûts d'API. Sans rentrer dans les détails techniques, ces protections permettent de limiter l'usage par utilisateur tout en garantissant une expérience fluide. Précisons que ce chatbot est actuellement en alpha : bien qu'accessible publiquement sur notre comparatif des modèles d'IA générative, il n'est pas encore 100% finalisé. Nous continuerons d'affiner le prompt, de surveiller les réponses et d'ajuster la configuration au fil des retours utilisateurs.
Côté timing, la création brute du chatbot - configuration dans Agent Builder, vectorisation des données, prompt initial, déploiement sur VPS - nous a pris environ deux jours. L'affinage s'étale ensuite sur quelques jours supplémentaires selon le niveau de précision attendu : chaque modification de prompt nécessite tests et benchmarks. Le gain de temps reste néanmoins significatif. AgentKit simplifie drastiquement la partie technique : gestion du RAG, interface conversationnelle, logique du modèle. Sans cet outil, développer un tel chatbot de zéro aurait demandé plusieurs semaines de développement front et back.