
Catalogue Apache Iceberg, parce que vous méritez mieux que FTP et CSV

Apache Iceberg interroge beaucoup. Son catalogue questionne tout autant. Découvrons le.
Après "Souveraineté par les données : Apache Iceberg, le format de table universel", partons à la découverte du catalogue d'Apache Iceberg.
Si Excel est l’outil des métiers, le format CSV est devenu au fil des années un standard pour les échanges de données ! Il est donc au data engineering ce que Excel est au métier.
Le format CSV est souvent utilisé avec le protocole d'échange FTP pour partager des données.
Cas d’usage *
Une organisation de type place de marché collecte des données de matériels agricoles disponibles à l’échange auprès de ses partenaires. Toutes les heures, l’ensemble de appareils disponibles est remonté par tous les acteurs vers la plateforme de centralisation.

Il n’y a pas de format standard d’échange : les adhésions se sont faites au fur et à mesure. Les dirigeants de la plateforme n’ont pas su imposer un format d’échange commun.
Il n’y a pas d’analyse des données échangées. L'intérêt de la plateforme c’est connaître à un instant t la disponibilité du matériel. Les analyses en profondeur n’existent pas : avec par exemple, pour objectif de se rendre compte que certains appareils et autres outils connaissent une certaine cyclicité. Leur indisponibilité régulière manifeste leurs pannes…
Il faut bien noter qu'ici ce n'est pas de l'échange de données mais de l'échange de fichiers. Il n’y a pas de garantie de délivrance de données : bien que le fichier soit parvenu au serveur FTP, il n’y a pas d'assurance que chaque ligne de données partagées soit correctement intégrée selon à une structuration cible.
(*) Bien sûr une architecture de services web peut-être envisagé.
La réalité terrain
Le cas d’usage pris en exemple ici existe dans de très nombreux secteurs ! C’est le cas dans le monde de l’assurance. Nombre de plateformes d’échange de données se base sur le format CSV. Les plateformes open data regorgent de fichiers CSV inutilisables.
Pas de données, pas d’IA ! Sans qualité de donnée, que des hallucinations !
Ces problèmes que nous évoquons ici vont être la source de mauvaises décisions. Et à l’heure de l’IA, ou de l’IA dite générative, la piètre qualité des données engendre des modèles tout aussi pauvres.
Apache Iceberg, un format d’échange ?
Apache Iceberg devient un format universel ! Il existe de plus en plus d’acteurs ayant fait le choix de s’interfacer avec Apache Iceberg.

Échanger de la donnée, la base de notre économie moderne
L’échange de données a pris une place très cruciale dans nos vies et dans notre réalité économique. Aucune organisation n’est complètement autonome et ne couvre 100% de toutes les activités qui lui incombent.
Ce principe est fondamental !
Et c’est pourquoi l’intégration de données occupe une telle place. C’est aussi pourquoi, il y a un grand nombre d’éditeurs de solutions logicielles qui rivalisent d'innovations pour s'imposer sur ce marché.
Et nous en convenons qu'il est peu simple de se retrouver dans une pareille jungle.
Il est important que toute organisation garde le contrôle de ses données. Les formats ouverts sont le fondement de cette vision.
Ainsi, Apache Iceberg se révèle être une solution pratique et pragmatique dans la reprise du contrôle de ses données. Elle joue aussi un rôle dans le partage de données. En particulier lorsque les données commencent à atteindre un certain volume.
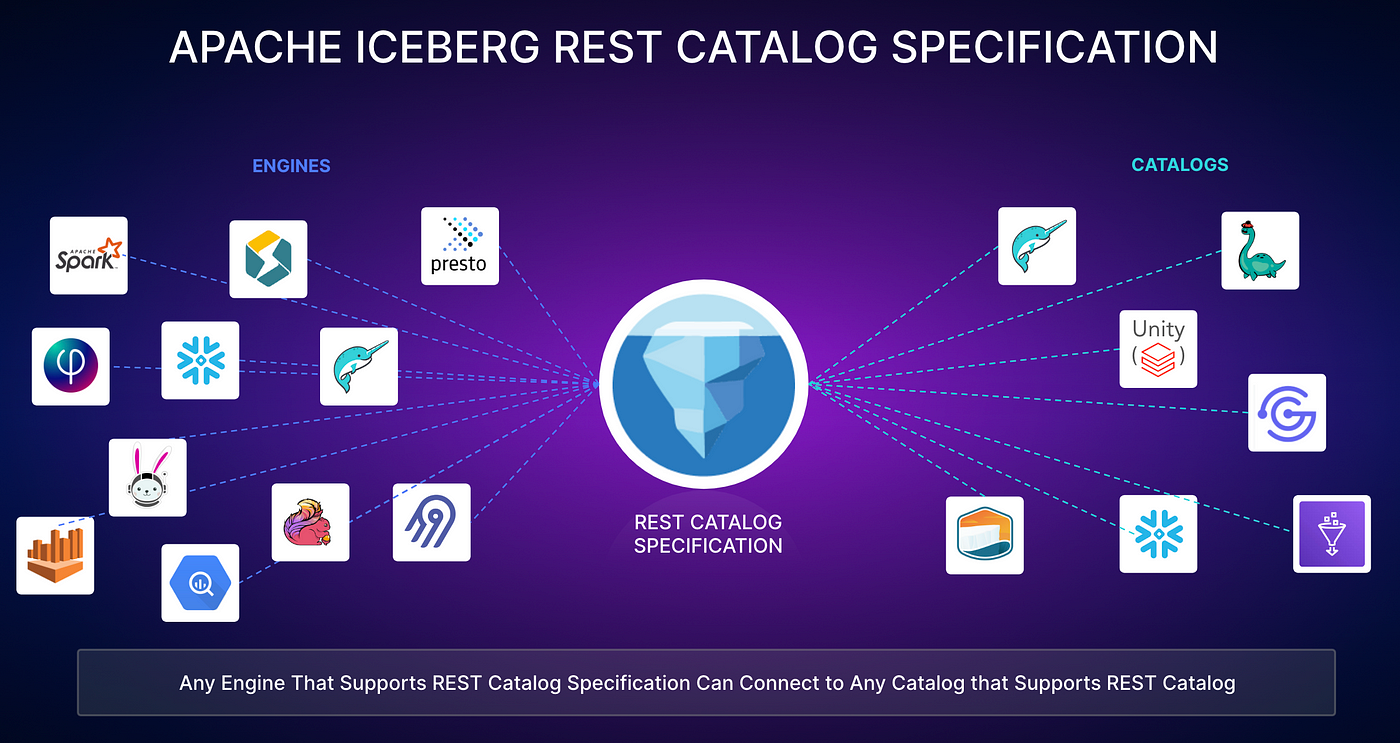
Apache Iceberg c’est aussi le catalogue (metastore)
L’ouverture apportée par le format a vite montré la nécessité de cataloguer les tables qui s’y trouvaient structurées et alimentées. Des métadonnées sur la donnée, sur les tables, sur les types, avec des statistiques sont venus augmenter le format. Pour retrouver aisément toutes ces métadonnées il était utile de les référencer afin de facilement les rechercher. En effet, les moteurs de calcul qui exploitent les tables au format Apache Iceberg ont ce besoin d’accès à ces métadonnées afin de parcourir efficacement les fichiers qui composent une table.
Le catalogue prend désormais une importance sans précédent. Les acteurs de ce marché se sont certes mis d’accord sur le format, mais s’entendent désormais sur le catalogue.
La gestion de données est clairement en train de vivre une révolution.
Il s’agit ni plus ni moins que d’avoir à la fois un format standard mais aussi un protocole commun afin d’accéder de la même manière à une donnée avec le moteur de calcul de son choix.
Pourquoi les catalogues des data lakehouse sont un sujet pour chaque organisation
Pour étayer les valeurs qui soutiennent les concepts portés par le catalogue Apache Iceberg, nous nous appuyons sur les solutions Nessie et Apache Polaris.
Portabilité des données, des tables
L'une des fonctions clés des catalogues dans l'écosystème Apache Iceberg est de conserver un enregistrement de chaque table, avec la correspondance de l'emplacement du stockage du dernier fichier metadata.json. Cela permet aux moteurs de requête d'interroger le catalogue et d'identifier l'emplacement précis des métadonnées actuelles de la table Iceberg. Sans cette fonctionnalité, il serait difficile pour les moteurs de requêtes de déterminer quel fichier metadata.json (qu'il s'agisse de v1.metadata.json, v2.metadata.json ou de quelque chose comme 84029348203984.metadata.json) est le bon pour interpréter la structure et l'état de la table de manière cohérente.
D’un point de vue métier, il s’agit de référencer ses données une et une seule fois ! Pas besoin de copier, et recopier, et transférer la donnée. On la crée, on la référence, on la partage en toute sécurité.
Accès unique et concurrent
Les catalogues Apache Iceberg jouent également un rôle crucial dans l'activation du contrôle de la concurrence au sein d'Iceberg. Les catalogues comme Nessie et Polaris utilisent une base de données avec des mécanismes de verrouillage pour garantir qu'une seule mise à jour de la référence d'une table peut se produire à un moment donné. De plus, pendant le processus de mise à jour, le rédacteur vérifie le catalogue pour le dernier fichier metadata.json avant et après une transaction. Il valide le numéro de séquence, en s'assurant qu'aucune autre écriture n'a été effectuée avant la confirmation de la transaction en mettant à jour la référence du catalogue. Ce mécanisme est essentiel pour maintenir les garanties ACID d'Apache Iceberg.
D’un point de vue métier, les organisations sont en mesure d’employer le moteur de requêtes qui est le plus efficace par rapport au cas d’usage : l’ingestion des données brutes peut se faire avec Talend ou Airbyte. Les traitements pour construire les couches bronzes, silver peuvent se faire avec Apache Flink afin de raffiner les données. Et la couche Gold, les données prêtes à l'emploi, est portée par Dremio.
Gouvernance portable, centralisée, partagée
Une évolution plus récente des catalogues est leur rôle de magasin pour les règles d'accès (RBAC), permettant une application cohérente des autorisations sur différents moteurs de requête. Nessie et Apache Polaris prennent en charge les mécanismes de définition des règles d'accès, permettant de contrôler les utilisateurs qui peuvent accéder à des objets spécifiques. Lorsqu'un utilisateur n'a pas l'autorisation d'accéder à une table particulière, telle que Table-A, le catalogue répond à la demande de métadonnées du moteur pour cette table avec une erreur "non autorisée". Cela déplace la gouvernance au niveau du catalogue, créant un point centralisé pour gérer l'accès plutôt que d'appliquer la gouvernance séparément pour chaque moteur.
D’un point de vue métier, la définition des règles d’accès ne s’opère qu’une et une seule fois et non dans chacun des moteurs de requête ou d’analyse (Comme avec une base de données).
Il faut aussi intégrer que de cette manière les autorisations s’appliquent bien aux tables, aux vues, aux colonnes, aux lignes ! Oui le moteur a les accès et les autorisations pour atteindre les fichiers mais le catalogue les abstrait, les masque complètement. Finalement, comme dans une base de données !
Versionning du catalogue
Nessie de Dremio a introduit une innovation : le concept de versionner le catalogue. Alors que les tables Apache Iceberg suivent nativement les versions au niveau de la table, le versionning du catalogue de Nessie capture des instantanés de l'ensemble des tables ainsi que leurs références de métadonnées. Il prend également en charge les commits (validations) tel que le propose le gestionnaire de code sources Git. Cela permet d'isoler les modifications sur plusieurs tables, ce qui favorise des fonctionnalités avancées telles que les transactions multi-moteurs, la gestion de branches, les restaurations (rollback) et la possibilité de créer des environnements sans copie pour l'expérimentation (bac à sable).
D’un point de vue métier, le versionning des données a été introduit il y a quelques années par des acteurs comme DVC. Aujourd’hui avec le rapprochement de tous les acteurs, l’échelle change. Les organisations sont dès lors en mesure d’isoler des traitements, sans copier et recopier les données. Il peut même être question d’avoir qu’un environnement de gestion de données et ce toujours sans recopier la donnée grâce à un mécanisme de branches. Ici, à l’heure du frugale, du changement climatique, réduire la quantité de matériels nécessaires à sa plateforme de données est plus qu'utile.
Gestion de Lakehouse
Les plateformes de données, qui intègrent un catalogue Apache Iceberg, offrent des fonctionnalités additionnelles ; elles sont considérées en véritable gestionnaire de data Lakehouse. Par exemple, le catalogue Apache Iceberg embarqué dans Dremio ou Snowflake, fournit une version avancée de ces technologies open source. Elle est enrichie de fonctionnalités de gouvernance, d'optimisation des tables, de nettoyage et de gestion des versions de catalogue, d'ingestion de données, le tout au sein d'une solution qui répond aux contraintes des entreprises. Cela simplifie grandement l'adoption et la migration vers Apache Iceberg.
Lorsque vous combinez toutes ces fonctionnalités avec la flexibilité de telles plateformes tant en cloud que sur site, et leur capacité à se connecter de manière transparente aux lacs de données, aux entrepôts de données et aux bases de données dans le cloud et sur site, vous obtenez une plateforme gouvernée pour toutes vos analyses.
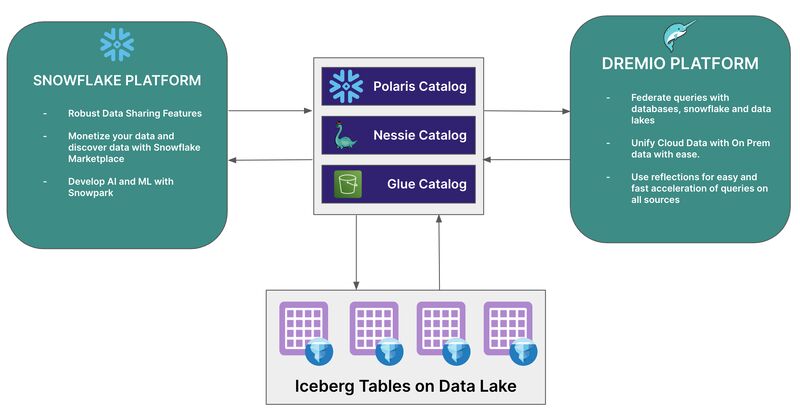
D’un point de vue métier, cela signifie que vous pouvez déployer, par exemple, Dremio, qui embarque un catalogue Apache Iceberg et commencer immédiatement votre projet ! Vous sécurisez l’accès à la solution, donc à votre catalogue. L’organisation se trouve ainsi prête à alimenter les tables en gardant le contrôle de ses données. Fort d’une telle architecture, vous pouvez avoir des flux de données en Apache Spark qui poussent vers le catalogue. Exploiter Snowflake pour calculer la données et y exécuter un certain nombre d’applications. Dremio rend toutes ses données accessibles par exemple à PowerBI.
Et notre cas d’usage dans tout ça
Il est certain que transformer les organisations avec les changements qui sont en train de s’opérer n’est pas une chose aisée. Néanmoins, face à tous ces bouleversements, chercher à garder le contrôle de ses données est une stratégie à suivre par toutes les organisations.

Ici, pour revenir au cas d'usage, cet acteur qui collecte les données des matériels agricoles disponibles à plusieurs intérêt à passer à un catalogue Apache Iceberg. Elle simplifie et sécurise l’accès aux données ; elle n’échange plus des fichiers mais bien des données. Les données sont échangées selon un Data Contract. Régulièrement, elle entretient le dialogue avec ses partenaires afin de faire évoluer le schéma. L'évolution du schéma de la table Apache Iceberg s’effectue sans altérer les données.
Cette organisation qui opère alors ses processus ETL au-dessus de table Apache Iceberg bénéficie de l’historisation des données pour tous ces traitements. Il ne lui est pas nécessaire de re-collecter les mêmes données auprès des systèmes opérationnels. Elle bâti directement depuis les tables Apache Iceberg des analyses, des statistiques avancées, des programmes de machine learning !