
Google Discover : un outil gratuit pour prédire le taux de clic des articles ? Testez-le ici

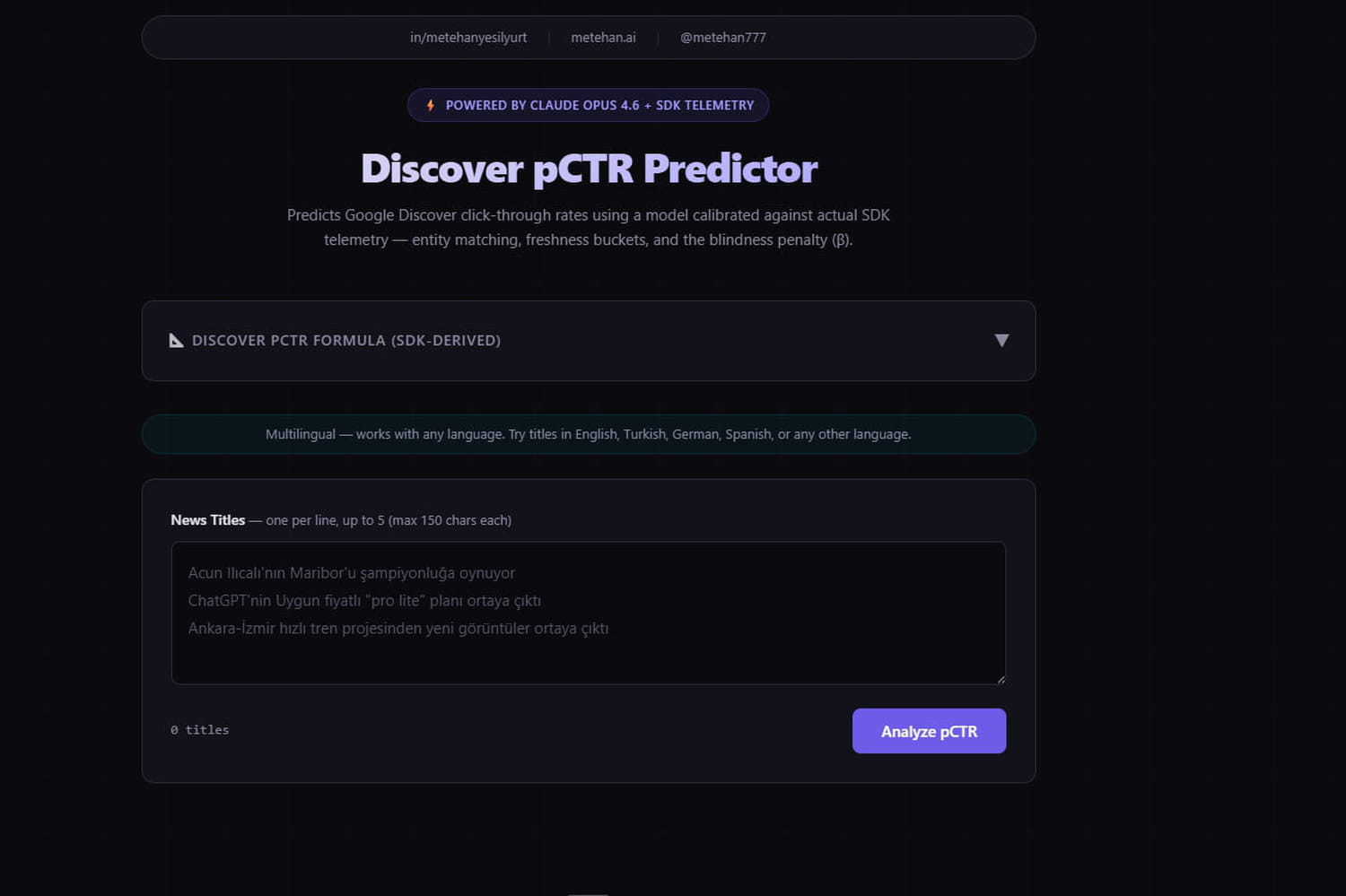
Et s'il était possible de prédire le taux de clic d'un article destiné à Google Discover ? Metehan Yesilyurt, consultant SEO turc, assure avoir développé un outil open source permettant de le faire, après avoir fouillé le SDK Android de Google et reconstitué le pipeline interne de Discover… Le Journal du Net a hébergé le code de cet outil sur ses propres serveurs et vous le propose gratuitement (cliquez sur l'image ci-après).
Pour comprendre comment Discover choisit les articles qu'il affiche, Metehan Yesilyurt n'a pas cherché à deviner. Il est allé lire le code de l'application Google sur Android. "Aucun système côté serveur n'a été sollicité", précise-t-il. L'expert SEO reste volontairement flou sur sa méthode exacte. Décompilation de l'application, interception du trafic réseau, inspection des logs Android ? Il ne le dit pas.
Commençons par le plus concret. Le titre d'un article dans Google Discover ne sert pas qu'à l'affichage. Metehan Yesilyurt a découvert qu'il "est extrait, sérialisé et transmis aux serveurs de Google" où il nourrit directement le modèle qui prédit si les gens vont cliquer ou non. C'est à partir de ce constat qu'il a construit son outil de prédiction : en analysant un titre sur 8 dimensions de qualité et en appliquant une pénalité clickbait, l'outil estime le taux de clic potentiel d'un article sur Discover. Un titre trop racoleur avec un score clickbait de 7/10 voit sa qualité chuter de près de 25%. Le tout passe dans une formule mathématique qui génère un taux de clic prédit, compris entre 0,5% et 22%.
Sur quoi repose le calibrage ? L'expert ne précise pas s'ils découlent directement de ce qu'il a observé dans le SDK ou s'il les a estimés.
L'outil développé par Yesilyurt est simple d'utilisation : vous entrez jusqu'à 5 titres d'articles, et une IA les passe au crible. En sortie, l'outil renvoie un taux de clic estimé pour Discover, accompagné d'un diagnostic détaillé et de suggestions d'amélioration pour chaque titre. Entrez votre titre dans le champ dédié de l'outil ci-dessous, que nous avons hébergé sur nos serveurs, en choisissant Claude Haiku 4.5 d'Anthropic comme modèle IA.
Une multitude de critères
Mais le titre n'est que la partie émergée de l’iceberg. En épluchant le SDK, Metehan Yesilyurt assure avoir mis au jour toute une série de mécanismes jusqu'ici non documentés :
- Un interrupteur par éditeur. Avant même d'évaluer si un article intéresse un lecteur, Discover vérifie un booléen (isCollectionHiddenFromEmberFeed), pour voir si un grand nombre d'utilisateurs Discover a masqué le domaine dans son flux. Si tel est le cas, l'article n'est pas poussé sur Discover.
- 7 jours pour exister. La fraîcheur est découpée en trois paliers : 1 à 7 jours (poids maximum pour être affiché), 8 à 14 jours (moyen), 15 à 30 jours (faible). Au-delà, la chute est continue, comptée en heures.
- 6 balises méta, pas une de plus. Pour construire une carte Discover, le SDK ne lit que six informations sur la page : l'image, le titre, le nom du site, la langue, la version sécurisée de l'image et le type d'accès (gratuit, payant, freemium). Si l'image ou le titre manquent, aucune carte n'est générée.
- Les web stories court-circuitent le classement. Elles disposent de leur propre pipeline de rendu et de leur propre moteur de recommandation, indépendant du ranking classique des articles.
- 150 tests A/B simultanés. A tout instant, un utilisateur Discover participe à environ 150 expériences côté serveur.
- Un système méconnu nommé NAIADES. Google utilise un moteur de personnalisation partagé entre plusieurs de ses produits, qui classe les contenus en 18 catégories. Parmi elles, une catégorie à part pour les éditeurs inscrits au Google Publisher Center : ces derniers bénéficient d'un traitement distinct dans le pipeline.
- Deux balises méta bloquent tout. Si votre CMS injecte nopagereadaloud ou notranslate en méta-tag, votre contenu n'entre tout simplement pas dans le pipeline Discover.
Metehan Yesilyurt détaille dans son article de blog de nombreux autres signaux, comme la gestion des notifications, les mécanismes de déduplication ou encore le rôle précis du score de qualité de l'image. Reste que ces découvertes appellent une lecture prudente. Certains de ces signaux étaient déjà soupçonnés par la communauté SEO, d'autres sont véritablement nouveaux. Et surtout, observer du code dans un SDK ne dit pas tout de la façon dont il est pondéré côté serveur.