
Les coulisses techniques de Netflix Le Big Data à très grande échelle, avec 100 To intégrés chaque jour
Beaucoup d'analystes attribuent le succès de Netflix à la qualité et la pertinence de son système de recommandation. Le service propose sans cesse de nouvelles séries, de nouveaux films, en fonction des goûts de chacun. Ce moteur de recommandation est une application Big Data par excellence puisqu'il s'appuie sur le comportement de chaque abonné. La plateforme de streaming alimente donc en permanence un data warehouse basé sur Amazon S3 d'une volumétrie supérieure à 10 Po. Celui-ci est alimenté quotidiennement par les 200 milliards d'événements générés par les abonnés, soit 100 To de données fraîches à intégrer chaque jour.
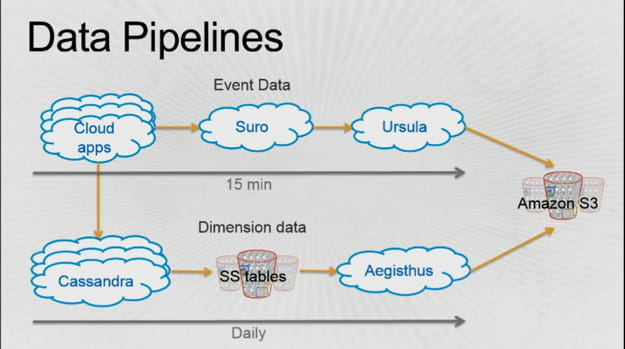
Entre un clic et le moment où l'événement est inséré dans le datawarehouse, il s'est écoulé moins de 15 minutes
Les recherches effectuées, les lectures de streams, mais aussi les interruptions de lecture, toutes ces données viennent alimenter les bases Netflix. Le datawarehouse Netflix compte 350 utilisateurs dont les analyses représentent 1,2 Po de données lues dans la base chaque jour. La plateforme Suro (composant de la plateforme Netflix OSS) effectue la capture des données, le logiciel Ursula qualifie ces événements et les injecte dans l'entrepôt de données. Entre le moment où l'utilisateur clique et celui où l'événement est inséré dans le datawarehouse, il s'est écoulé moins de 15 minutes. Les données relatives aux abonnements sont mises à jour via l'outil Aegisthus de manière incrémentale sur un rythme quotidien.
Netflix travaille avec Twitter, Cloudera et MapR sur le projet Parquet
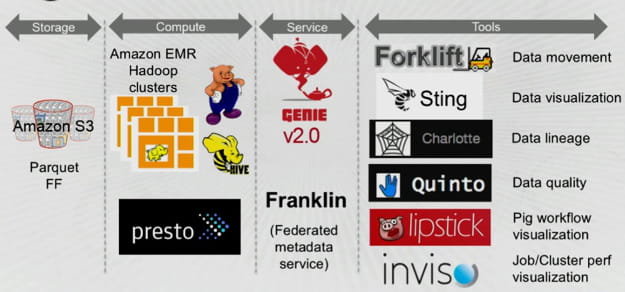
Le datawarehouse est intégralement stocké sur Amazon S3. Netflix a fait le choix du format de fichier Parquet, jugé plus performant pour le stockage de données en colonnes que le format SequenceFile, notamment pour la compression de données et les temps de lectures. Netflix travaille avec Twitter, Cloudera et MapR sur le projet Parquet.
Un entrepôt de données sous Hadoop 2.4
En 2014, Netflix a migré l'ensemble de son datawarehouse sous Hadoop 2.4. Ce cluster est exposé sous forme de Web Services aux applications via la solution Genie 2.0. Pour exécuter des requêtes sur le cluster Hadoop, les ingénieurs de Netflix ont fait le choix d'utiliser le langage Pig et du moteur d'exécution Tez. Celui-ci vient se placer au-dessus d'Hadoop et a permis à Netflix d'optimiser le fonctionnement des traitements de son cluster Hadoop 2 et de réduire les échanges engendrés sur le réseau. Les gains mesurés par Netflix sont substantiels, avec des temps de traitement divisés par 1,2 dans le pire des cas mais jusqu'à 14 fois pour certains jobs, selon le traitement demandé. "Pig on Tez " est une solution développée avec LinkedIn, Hortonworks et Yahoo!
Les analystes peuvent aussi réaliser des recherches interactives via le moteur SQL distribué Presto, un moteur développé en collaboration avec Facebook. Ce moteur réussit le tour de force de pouvoir réaliser des requêtes dans un SQL tout ce qu'il y a de plus standard sur Amazon S3 et sur une base de données de plusieurs pétaoctets et de façon interactive.