
Le code, une source de vulnérabilités à prendre au sérieux

Lorsque l'on parle d'écrire du code sécurisé, on fait généralement référence à la création d'applications sécurisées. Il s'agit notamment d'écrire du code qui ne crée pas de vulnérabilités lorsque notre application est en cours d'exécution. Mais qu'en est-il du code lui-même ? Nous supposons souvent à tort que le code source étant privé, il peut être considéré comme sûr. Mais les acteurs malveillants savent que l'accès au code source peut exposer des menaces actives.
Le code est un actif largement distribué

Le code est l’un des actifs les plus précieux d'une entreprise, mais il est aussi, par nature, très distribué. Il est presque impossible d'empêcher le code source de se disperser dans votre organisation. Il est poussé dans votre système de contrôle de version, probablement git, puis cloné sur les machines de vos développeurs (professionnelles et bien souvent personnelles aussi), inclu dans de nouveaux projets, collé dans des wikis internes, sauvegardé dans le cloud, partagé par des systèmes de messagerie comme slack et même posté dans des forums publics comme StackOverflow. De plus, avec git, le code n'est jamais vraiment supprimé. Lorsqu'une ligne de code est supprimée, elle est en fait simplement remplacée par de nouveaux ajouts, la version précédente étant toujours accessible sous une pile d'anciens commits. Indépendamment de la façon dont votre code est géré, le fait est que vous n'avez aucune visibilité sur les endroits où il pourrait se retrouver, aucun moyen de vérifier qui a accédé au code ou l'a cloné, aucun moyen de savoir avec certitude qu'il est toujours sous contrôle.
Ne vous méprenez pas, je ne plaide pas pour un contrôle d'accès ultra-strict au code source, ni pour son verrouillage par de multiples couches d'authentification. Mais si j’attire votre attention sur sa tendance à la dispersion, c’est pour illustrer le fait que votre code source et tout ce qu'il contient (nous y reviendrons plus tard) doit être considéré comme vulnérable.
Vous pouvez argumenter que tous ces systèmes dans lesquels le code peut se retrouver sont toujours privés et sous contrôle d’un système d'authentification, et donc qu’il n’y a donc pas de risque de sécurité. Malheureusement, ce n'est pas le cas. Les dépôts de code sont connus comme étant une cible de choix pour les attaquants car ils contiennent de nombreuses informations sensibles. Récemment, nous avons constaté une augmentation massive du nombre d'attaques ciblant des dépôts git privés.
Ciblage des dépôts git par des attaques de type supply chain
Une attaque de la supply chain logicielle se produit lorsque des pirates manipulent le code de composants logiciels tiers afin de compromettre les applications "en aval" qui les utilisent. Nous avons assisté à une augmentation spectaculaire de ce type d'attaques.
Un exemple récent est le cas CodeCov en 2021. Dans cet exemple, les attaquants ont pu compromettre CodeCov en utilisant des informations d'identification trouvées dans une image docker mal configurée. Grâce à ces informations d'identification, les attaquants ont pu accéder au dépôt de code privé de CodeCov et insérer une ligne de code malveillante. Cette ligne de code capturait les informations d'identification utilisées dans l'environnement d’intégration continue et les envoyait directement à l'attaquant. Bien que les attaquants aient eu accès à une pléthore d'informations d'identification potentiellement sensibles, l'analyse du chemin d'attaque nous permet de voir ce qu'ils recherchaient réellement, à savoir des informations d'identification pour les dépôts de code privés. Autrement dit, ils ont considéré que le code source entreposé dans ces dépôts était un objectif prioritaire, permettant de s’introduire dans d’autres systèmes et donc de maximiser l’impact de leur opération. Au moment de l’attaque, CodeCov comptait 22 000 clients, et l’intrusion n'a pas été détectée pendant des mois. Les communications de sociétés telles que Rapid7, Twillio, Confluent et Atlassian nous ont par la suite appris que les attaquants avaient ciblé leurs dépôts git privés et avaient pu y accéder.
Recherche de dépôts git mal configurés
Une autre technique courante utilisée par les attaquants pour accéder aux dépôts de code privés est le "fuzzing" de domaines, pour identifier les dépôts .git mal configurés, ouverts aux accès non autorisés. Cette technique a été utilisée lors d'une récente attaque de SakuraSamurai contre le gouvernement indien (il convient de noter qu'il s'agissait d'une attaque éthique, réalisée par un groupe de hackers white hat).
Tout d'abord, les attaquants ont utilisé des outils pour trouver de multiples sous-domaines liés à leurs sites cibles, puis, ils ont commencé à rechercher des répertoires .git côté client qui permettaient un accès à distance. Au total, ils ont trouvé des informations d'identification codées en dur dans 10 dépôts git distincts et mal configurés.
Vous seriez surpris du nombre de dépôts git, côté serveur ou côté client, qui permettent l'accès à distance.
Cibler les systèmes de messagerie internes
L'un des scénarios préférés des attaquants consiste à accéder aux systèmes de messagerie internes des entreprises. Cela peut se faire de différentes manières. Vous pouvez utiliser des techniques de phishing sophistiquées ou simplement acheter un cookie de session sur le marché noir. Une fois dans Slack, vous pouvez scanner les canaux à la recherche d'informations sensibles, de code source ou bien même convaincre les administrateurs de vous donner accès à des systèmes protégés. C'est exactement ce que les pirates ont fait pour accéder à la codebase de EA games.
Il existe de nombreux autres exemples d'exposition de code source et de techniques différentes utilisées par les attaquants. Le but n'est pas de tous les énumérer, mais plutôt de démontrer que le code source et les dépôts git, en particulier, ne sont pas des coffres-forts sûrs et constituent souvent une faiblesse dans la défense d'une entreprise.
Menaces au sein du code source
Vous êtes peut-être familier avec les failles de sécurité externes de votre application, par exemple, le Cross-Site Scripting ou l'injection SQL, mais qu'en est-il de votre code source lui-même ? Votre code source peut être une vulnérabilité en soi.
Examinons donc les menaces actives et passives. Les menaces actives sont des éléments qui peuvent être immédiatement utilisés dans une attaque, notamment les secrets présents dans le code (clés et informations d'identification API, etc.). Les menaces passives sont des menaces qui peuvent être utilisées par un attaquant pour cibler les points faibles de votre application.
Menaces actives
Secrets
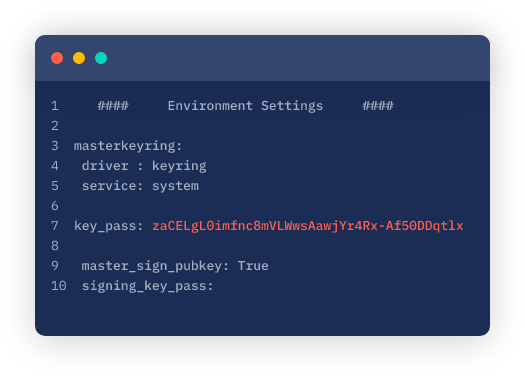
L'exemple le plus évident est celui des secrets. Les secrets sont des éléments tels que les clés d'API, les certificats de sécurité, les clés d’accès de base de données et tout ce qui permet d'accéder aux systèmes et aux services. Nous utilisons les secrets pour nous authentifier et authentifier nos systèmes auprès de notre application et nous pouvons avoir des centaines de secrets à gérer. Pensez à tous les services dont votre application peut disposer, qu'il s'agisse d'outils SaaS, d'infrastructures dans le cloud, d'outils d'alerte ou de tableaux de bord. Tous ces systèmes utilisent des secrets.
Ces secrets sont conçus pour être utilisés de manière programmatique, et se retrouvent donc souvent dans le code source. En outre, lorsque vous utilisez un système de contrôle de version comme git, vous devez vous rappeler que l'historique est figé, à moins que vous ne le réécriviez. C'est pourquoi des secrets peuvent être enfouis dans votre historique git, sans que vous puissiez les découvrir, mais ils peuvent l‘être facilement par un attaquant qui sait ce qu'il cherche.
Des secrets sont très souvent trouvés dans les dépôts git, parfois à cause de mauvaises pratiques comme le codage en dur des secrets, parfois à travers des fichiers générés automatiquement comme les journaux de débogage. Ils peuvent être inclus dans des fichiers de configuration qui sont accidentellement ajoutés dans git, ou ils peuvent être gérés activement dans git. C'est, bien sûr, une terrible erreur si l'on considère à quel point le code source peut fuiter. Pourtant, de nombreuses entreprises utilisent git pour distribuer des secrets aux développeurs, ce qui peut causer un énorme risque de sécurité. Non seulement vous n'avez aucun journal d'audit sur les personnes ayant accès à ces dépôts, mais vous avez également peu de contrôle sur l'endroit où ils aboutissent.
Une étude publiée récemment a mesuré l'étendue de cette exposition de secrets dans les dépôts de code publics. Sur une période d'un an, 2 millions, oui millions, d'informations d'identification ont été divulguées sur des dépôts publics GitHub. Mais il n'est pas nécessaire de chercher bien loin pour trouver des exemples de secrets divulgués dans des dépôts privés qui ont également été exploités lors d’attaques. Uber a connu ce type d’attaques lorsque des pirates ayant eu accès à ses dépôts GitHub privés ont découvert des informations d'identification.
Données personnelles

Il est très courant que les données personnelles coexistent avec le code source. Il peut s'agir d'un dump de base de données ou de journaux de débogage qui ont été ajoutés dans le dépôt. Une fois que ces données se retrouvent au même endroit que le code source, elles sont clonées et copiées avec lui. Non seulement cela peut constituer une menace pour vos utilisateurs, mais cela peut également avoir un impact énorme sur la conformité. C'est exactement le type d'informations découvertes lors de l’attaque faite sur le gouvernement indien. Il s'agissait notamment de dumps MySQL, mais aussi de rapports de police sensibles qui avaient été intégrés dans l'historique des dépôts git.
Menaces passives
Failles relatives à la cryptographie
Il peut y avoir de nombreuses failles dans votre cryptographie, y compris l'exposition de la clé de cryptage (qui serait considérée comme un secret), mais le simple fait de montrer la méthode de cryptage peut elle-même constituer une menace pour la sécurité. La cryptographie a tendance à être forte au départ, puis à s'affaiblir progressivement. Par conséquent, si vous continuez à utiliser une technique de cryptographie ancienne, vous diminuez votre niveau de sécurité. Cela signifie que les méthodes de cryptage doivent être continuellement améliorées.
Cela étant dit, l'utilisation d’approches de type “brute force” pour tenter de déchiffrer des données cryptées n'est généralement pas la première tactique employée par les attaquants. En effet, il est difficile, voire impossible, de déterminer quelle méthode de cryptage a été utilisée et s'il est même possible de la décrypter. Cependant, si vous utilisez un cryptage faible ou un cryptage présentant des vulnérabilités connues et que cela est écrit dans votre code source, cela peut orienter un attaquant directement vers des données non sécurisées dans votre application.
Un exemple de ceci serait l'utilisation de l'algorithme de hachage MD5 pour hacher vos mots de passe. Voici ce que relève une étude de 2008 CompTIA Security+ 2008 in depth : "Au milieu des années 1990, des failles ont été révélées dans les fonctions de compression, et 10 ans plus tard, des attaques réussies sur MD5 ont été menées". Gardez à l'esprit qu'il s'agit d'une étude de 2008 et que, plus de 20 ans plus tard, nous utilisons toujours le MD5 pour hacher les mots de passe.
Logique métier / d’application
Les vulnérabilités de type logique métier sont des failles dans la conception et la mise en œuvre d'une application qui permettent à un attaquant de provoquer un comportement non souhaité. Contrairement aux autres vulnérabilités énumérées, ces failles peuvent être exploitées à partir de l'application en cours d'exécution et un attaquant n'a pas besoin du code source pour les découvrir. Mais dans certains cas, cela peut considérablement aider un attaquant à cibler des zones spécifiques d'une application.
Voici quelques exemples de vulnérabilités courantes dans la logique métier : une confiance excessive dans les contrôles côté client, l'incapacité à gérer les entrées non-conformes et les hypothèses erronées sur le comportement des utilisateurs.
Une fois qu'un attaquant a accès à votre code source, il peut facilement cartographier les endpoints d’une API et découvrir les hypothèses que les développeurs ont faites sur la façon dont elle sera utilisée.
Dépendances
Dans la grande majorité des applications actuelles, 90 % du code provient de bibliothèques open-source, d'outils SaaS et d'autres composants externes. Cela signifie que, la plupart du temps, les pirates connaissent votre code mieux que vous, car ils étudient ces composants et savent comment les exploiter.
La première étape pour lancer une attaque contre votre application sera d'essayer de déterminer quelles sont les dépendances vulnérables sur lesquelles repose votre application.
Des outils comme Snyk disposent de bases de données listant les vulnérabilités connues dans ces composants, et une simple analyse peut vous permettre de savoir sur quelles vulnérabilités critiques votre application repose. Il peut même être possible de télécharger sur Internet du code exploitant automatiquement cette vulnérabilité.
Bien sûr, vous pouvez argumenter et dire que vous pouvez découvrir les dépendances par le biais d'une analyse statique, mais cela n'est vrai que pour ce à quoi vous, l'utilisateur, avez accès. Pour obtenir la liste la plus complète de vulnérabilités, vous devez avoir accès au code source de l'application dont vous dépendez. Si un attaquant obtient l'accès à ce code source, il peut produire une liste de cibles et de failles qu'il peut potentiellement exploiter contre votre application.
Prévenir la création de code source non sécurisé
En matière de sécurité, il n'existe pas de solution miracle qui résout tous les problèmes, et il en va de même pour le code source. Il est plus raisonnable de partir du principe que que tout ce qui est contenu dans le code source sera, un jour ou l'autre, exposé et donc commencer à prendre des mesures appropriées pour empêcher des vulnérabilités de pénétrer dans ce code source.
Revues de code
La protection du code source repose sur l'éducation, les revues de code, les outils et sur le fait de savoir où concentrer ses efforts. En 2015, AppSec USA a réalisé une enquête sur où et comment les vulnérabilités sont découvertes.
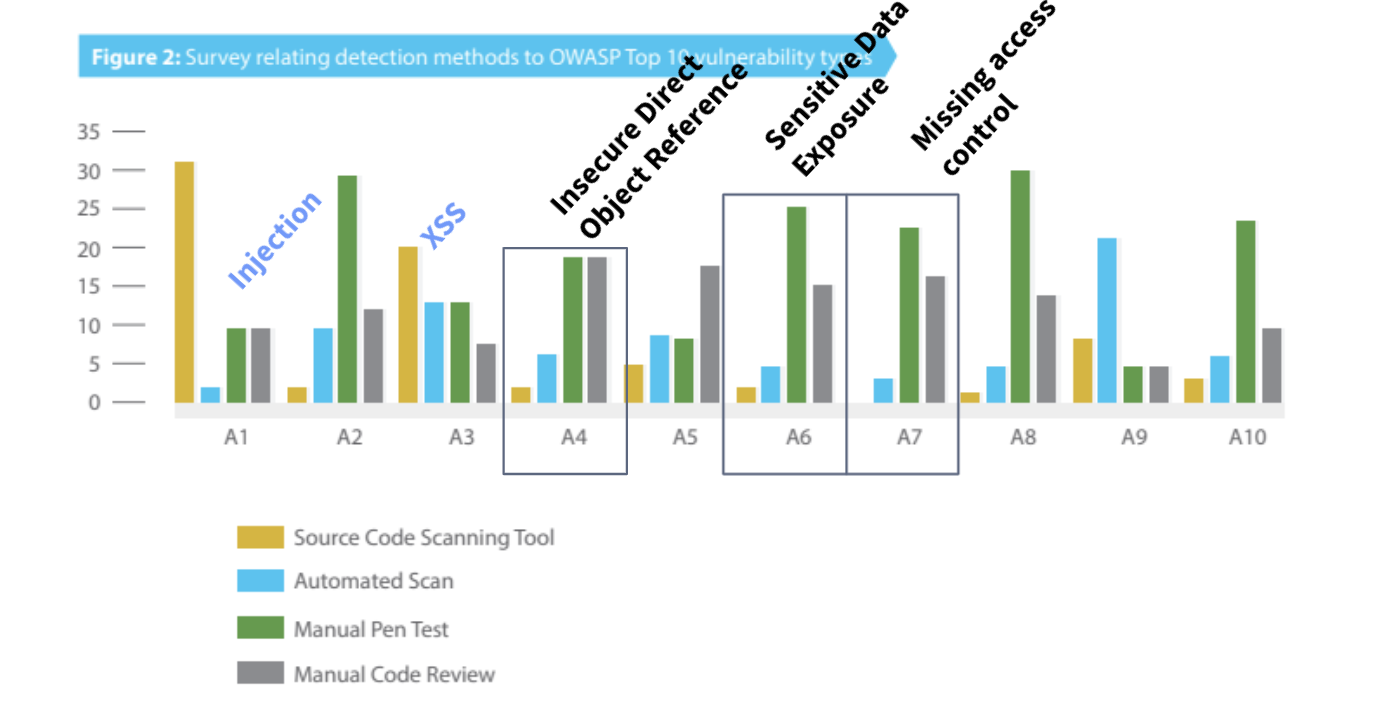
Cette étude montre quelles vulnérabilités sont le plus souvent manquées par les outils automatisés, et ce qui a été le plus souvent détecté. Dans ce cas, la référence directe à un objet non sécurisé, l'exposition de données sensibles et l'absence de contrôle d'accès sont les éléments les plus fréquemment manqués par les outils automatisés.
Cela donne une excellente indication des vulnérabilités sur lesquelles un processus manuel tel que les revues de code est efficace, , et celles qui peuvent être collectées de manière fiable par des outils automatisés. La meilleure ressource pour cela est le Guide de revue de code de l'OWASP.
Détection automatisée des secrets
Les secrets sont l'une des vulnérabilités les plus dangereuses pouvant être exposées dans votre code. Ce sont les clés de votre organisation qui peuvent donner accès aux informations et aux systèmes les plus sensibles. Si un attaquant utilise des informations d'identification, il peut être particulièrement dangereux car, une fois correctement authentifié, il peut rester incognito pendant de longues périodes, se déplacer latéralement dans les systèmes, élever ses privilèges et collecter des informations.
Les secrets peuvent être enfouis dans l'historique d'un dépôt git ou dans les journaux de débogage et autres fichiers générés automatiquement. Ils sont donc impossibles à détecter à l'aide d'outils classiques d'analyse statique ou de revues de code manuelles, qui ne “voient” que de la version actuelle du code source. C’est pourquoi il est essentiel de mettre en place une détection automatique des secrets à l'aide d'un outil dédié.
DevSecOps
Trop souvent, la sécurité est restreinte à un département d'experts en sécurité, mais les développeurs peuvent et doivent en partager la responsabilité. Le DevSecOps est le concept qui consiste à intégrer les développeurs dans le processus de sécurité dès le début. Personne n'est plus proche du code source que les développeurs. Il est donc logique qu'ils partagent une partie de la responsabilité de s'assurer que le code est sécurisé. Cela signifie non seulement que les vulnérabilités ne sont pas introduites dans le code source, mais aussi que nombre d'entre elles sont détectées plus tôt, ce qui réduit le coût des mesures correctives. Cela ne signifie pas que vous pouvez vous passer d’une équipe de sécurité, mais que vous pouvez augmenter et améliorer votre couverture globale tout au long du cycle de développement du logiciel.
Pour conclure
Le code source est un actif précieux mais très sensible aux fuites. Il est très difficile d'empêcher les fuites de code source et le protéger par de lourdes couches d'authentification ne fera que ralentir le processus de développement. Si nous pouvons difficilement contrôler les fuites du code source, nous pouvons en revanche contrôler les vulnérabilités qu’il peut exposer. Il peut s'agir de menaces actives, comme la fuite de secrets et de données personnelles, ou de menaces passives, comme les failles de cryptographie, les failles de logique métier ou applicative et les vulnérabilités provenant des dépendances. La clé pour pouvoir se protéger est de comprendre ce qui peut être évité à l'aide d'outils, et ce sur quoi nous devons nous concentrer lors des revues de code. En fin de compte, personne n'est plus proche du code source que les développeurs, de sorte que sa protection nécessitera sans aucun doute un modèle de responsabilité partagée entre l'équipe de sécurité, les équipes opérations et les développeurs eux-mêmes (DevSecOps). En fin de compte, toutes les organisations devraient s'efforcer d'avoir un code source qui pourrait être distribué en open source à tout moment sans créer des failles de sécurité supplémentaires.