
SEO : comment améliorer le crawl de son site en 3 étapes
Les robots de crawl n'ont pas une minute à perdre. Sur chaque site, ils visitent non seulement les nouvelles pages mais aussi certaines anciennes. Et le passage des robots est vital car, rappelle Alexis Mouton, directeur de mission SEO pour l'agence SEO Clustaar, "une page qui n'est pas crawlée régulièrement n'a aucune chance de se positionner durablement". Cependant, les robots ne consacrent à chaque site qu'un temps limité, appelé "budget de crawl", lui-même dépendant de la popularité du site. Pas question pour eux, dans ces conditions, de crawler l'intégralité des pages à chaque fois. Voici comment les orienter vers les meilleures pages d'un site.
1. Trouver les pages qui gaspillent du budget de crawl
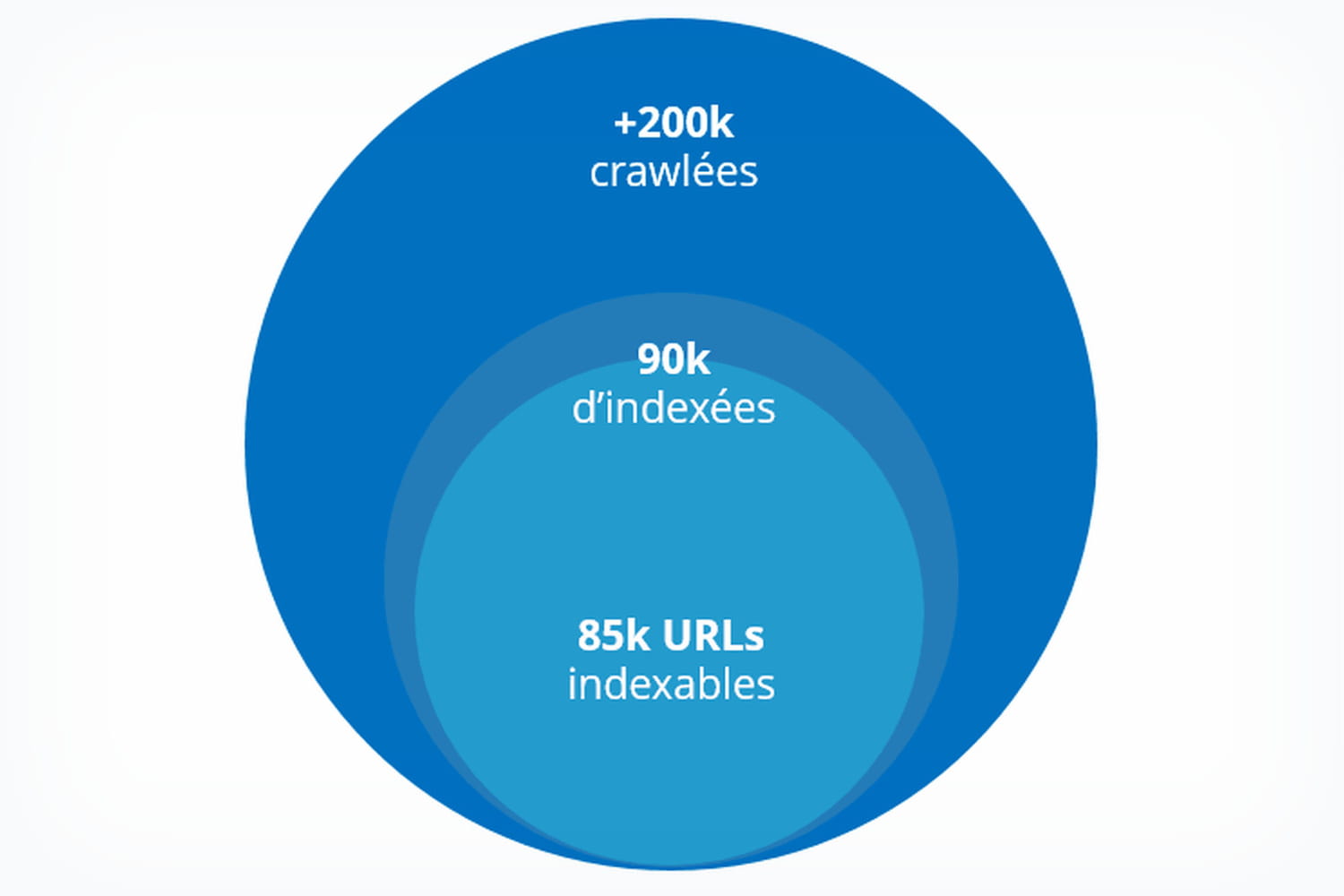
Parmi toutes les pages que les robots crawlent sur un site, il faut tout d'abord identifier celles qui lui font perdre du temps et affaiblissent les performances SEO. "La nouvelle Search Console de Google est aussi un outil d'optimisation du budget de crawl, car elle donne des informations de plus en plus complètes sur l'indexation", remarque Alexis Mouton, qui l'utilise quotidiennement pour analyser le crawl de ses clients. Dans l'onglet "couverture", Google présente le nombre de pages "exclues", c'est-à-dire crawlées et non indexées. Dans le tableau sous ce graphique, des précisions sur les raisons pour lesquelles ces pages sont exclues donnent un premier angle d'analyse et une idée du volume de pages concernées : balises canoniques absentes entre deux pages de contenu identique, présence de la balise <noindex>, pages avec redirection, etc. Ces pages gaspillent du temps de crawl.
Il faut s'attaquer à l'analyse des logs pour connaître le volume exact de budget de crawl gâché. Céline Mazouffre, consultante pour l'agence de conseil en stratégie et marketing Resoneo, rappelle que les robots de Google se reconnaissent à deux signes : l'adresse IP commençant par 66.249 et un user agent "googlebot". Elle recommande d'isoler les logs reliés au moteur de recherche pour observer d'une part le volume de pages crawlées, à comparer avec le nombre de pages du site, d'autre part l'importance des pages crawlées. Cette analyse permet de savoir quel pourcentage du site est réellement crawlé, quelles pages clés pour le SEO ne bénéficient pas des visites des moteurs et par la faute de quelles pages, qui ne devraient pas faire perdre du temps aux crawlers.
Ces informations permettent de savoir si l'optimisation du crawl doit être une priorité pour le site. "L'idéal, rarement atteint, c'est d'obtenir que les moteurs crawlent 100% des pages stratégiques", mais Céline Mazouffre nuance. "Des seuils permettent de définir l'urgence de ce travail : 85% de pages crawlées, c'est bien. Moins de 70%, c'est moyen, et en dessous de 25%, c'est très mauvais et il faut très vite réagir".
2. Diriger les robots vers les bonnes pages
Il y a deux manières d'optimiser le crawl. La première consiste à orienter les robots vers les pages stratégiques pour le SEO. "Les robots des moteurs de recherche doivent accéder aux pages intéressantes en moins de trois clics", assure Céline Mazouffre. "Pour optimiser le nombre de clics, la home page doit renvoyer vers les pages catégories et celles-ci vers n'importe quelle page produit en moins de deux clics. C'est réalisable avec un bon système de pagination dichotomique (c'est-à-dire un découpage des numéros de pages permettant d'en faire apparaître certaines en masquant les autres de manière dynamique en fonction des clics de l'utilisateur).
Le maillage interne facilite le parcours du robot sur le site. Si une page reçoit plus de liens que les autres, le robot a plus de chances de tomber régulièrement dessus. Le référenceur doit donc veiller à ce que les pages vers lesquelles pointent le plus de liens internes soient les pages les plus importantes.
3. Eloigner les robots des pages à ne pas indexer
La seconde méthode pour optimiser le crawl, c'est de tenir les robots à distances des pages peu importantes pour le SEO. La balise <noindex>, dans le code HTML d'une page, leur indique qu'il ne faut pas l'indexer, mais ne les empêche pas de la crawler. Le fichier robots.txt reste donc l'outil le plus sûr et Céline Mazouffre encourage les référenceurs à le maintenir à jour et à définir des règles de crawl en adéquation avec la stratégie du site. Alexis Mouton évoque le site d'un client dont le trafic SEO baissait depuis quelques mois. L'analyse des logs a révélé que "Google passait beaucoup de temps à crawler des URLs contenant des filtres, inutiles pour le SEO". En bloquant ces pages dans le robots.txt, il a redirigé le crawl vers les pages stratégiques et le trafic a recommencé à croître.

Plus étonnante, la méthode pratiquée par Céline Mazouffre consiste à utiliser des liens en JavaScript vers les pages que les robots ne doivent pas visiter. Les moteurs de recherche ne peuvent pas les suivre s'ils sont intégrés sur un événement JavaScript, comme un clic, par exemple. Dans le cas d'une refonte de site, la consultante recommande même de garder les pages à ne pas indexer en JS dynamique. Inutile de les passer en pré-rendering et non seulement elles seront très ergonomiques, mais en plus, avec un maillage adapté, elles ne seront ni crawlées, ni indexées. "Cette méthode est très efficace pour compléter un fichier robots.txt", conclue-t-elle.