
Comment Facebook a bâti son moteur de recherche "Graph Search" Comment Facebook a bâti son moteur "Graph Search"
Déjà lancé depuis plus d'un an aux Etats-Unis, et en Angleterre il y a quelques mois, le Graph Search de Facebook n'est pas un moteur comme celui de Google. Il se concentre sur les liens existant entre les entités du réseau social, c'est-à-dire les utilisateurs et leurs amis, les lieux où ils sont allés, les choses qu'ils aiment etc.
Le moteur de Facebook s'intéresse en fait autant aux entités elles-mêmes qu'aux liens qui les relient, le terme "Graph" désignant d'ailleurs les liens tissés entre ces entités. Hautement personnalisés, plus encore que ceux remontés par Google, les résultats proposés par le "Graph Search" diffèrent largement d'un utilisateur à l'autre, en fonctions des liens (des "likes", par exemple) qu'ils ont tissés avec d'autres entités.
Graph Search : des techniques connues et des particularités
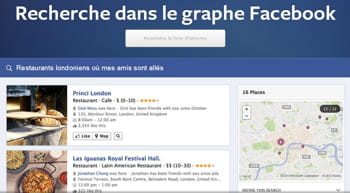
Pour autant, afin de mettre en place son moteur, Facebook a tout de même dû employer des techniques bien connues, et semblables à celles déjà utilisées par Google et d'autres moteurs classiques, tout en y ajoutant quelques particularités, pour y injecter la dimension sociale notamment.
Comme souvent avec ses projets informatiques, le moteur a expliqué de façon assez détaillée sa manière de procéder, en n'étant pas avare en détails techniques. Une ouverture dont Facebook a aussi fait preuve avec ses data centers et son initiative d'Open Hardware Open Compute.
Ainsi, le responsable de l'ingénierie de Facebook, Lars Eilstrup Rasmussen, un transfuge de chez Google qui a co-fondé Google Maps, explique dans un billet officiel que le moteur de recherche que voulait Facebook devait pouvoir gérer les connexions de plus d'un degré. Par exemple : les restaurants aimés par mes amis (premier degré) originaires d'Inde (deuxième degré). "Par chance", raconte l'ingénieur, "au moment de se lancer dans ce projet, Facebook utilisait déjà en interne un système qui avait justement cette fonction : Unicorn."
Unicorn, un index inversé devenu "Graph Search"
Unicorn est plus précisément un index inversé, un composant fondamental bien connu dans l'univers des moteurs de recherche. Dans un autre billet officiel, des ingénieurs de Facebook expliquent que dès fin 2010, ce système Unicorn était utilisé au sein du réseau social, sous la forme d'une base de données "in memory" (c'est-à-dire exécutée en mémoire RAM, pour gagner en performance), pour faire remonter des entités en fonction de combinaison d'attributs, c'est-à-dire en fonction des liens du graph pouvant ainsi devenir des requêtes. Dès 2011, Facebook décide de faire d'Unicorn la base de son futur moteur de recherche. Unicorn sera à la fois la solution qui bâtit et gère cet index, mais aussi celle qui va faire remonter des données en réponse à une requête.
MapReduce, Hive, Hbase, Hadoop... Graph Search s'appuie sur des technologies Big Data.
C'est donc Unicorn qui indexera les entités et leurs liens, et les fera remonter en réponse à une requête. "Le moteur de Facebook marche comme un moteur de recherche par mot clé, sauf que les mots clés décrivent les liens au sein du graph plutôt que du texte présent dans les documents et pages web", résument ainsi les ingénieurs de Facebook dans le billet "Under the Hood: Building out the infrastructure for Graph Search". Bien sûr, Unicorn permet de répondre aux requêtes des internautes en leur proposant des résultats pertinents, tout en s'assurant qu'ils ne verront que le contenu auquel ils peuvent avoir accès (voir comment sur la page suivante).
Le Big Data au secours de Facebook et son moteur de recherche
Facebook a cependant dû étendre les possibilités de son Unicorn pour mettre au point son moteur de recherche. Pour cela, comme le détaille le billet, l'entreprise de Mark Zuckerberg a eu recours à des technologies moins originales, et même classiques pour les moteurs de recherche traditionnels. Ces technologies sont d'ailleurs aujourd'hui constitutives du Big Data (les liens entre moteur de recherche et Big Data étant très étroits).
Par exemple, au sujet de la recherche de posts, le réseau social a ainsi expliqué que l'indexation est "une combinaison de scripts MapReduce collectant les données depuis des tables Hive, les traitrant et les convertissant dans la structure adaptée à l'index inversé. Les données collectées sont stockées dans un cluster Hbase, depuis lequel sont exécutés des jobs Hadoop destinés à bâtir l'index via des procédés largement parallélisés. Ce procédé d'indexation convertit les données brutes dans un index qui fonctionne avec Unicorn, l'infrastructure du moteur de recherche." MapReduce, Hive, Hbase, Hadoop... autant de termes qui renvoient au Big data et le définissent.
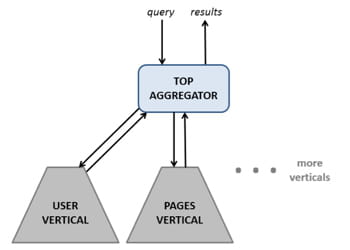
Face à l'énorme quantité de données à traiter, le réseau social a aussi révélé que chaque type d'entité dispose d'un serveur d'index Unicorn vertical, chapeauté par "des agrégateurs" : les requêtes faites sur le système Unicorn sont ainsi envoyées à à ces agrégateurs, qui vont les ventiler sur leurs différents serveurs d'index, ces derniers faisant ensuite remonter leur réponse à cet agrégateur.