
Déployer dans Windows Azure : les différents services, et les impacts sur votre solution .NET

Découvrez notre retour d'expérience sur les services d'hébergement proposés sur Azure, et les impacts auxquels nous avons dû faire face lors du déploiement d'une application .NET classique.
Déployer dans Windows Azure : les différents services, et les impacts sur votre solution .NET
On distingue sur chacune des grandes plateformes de cloud (Azure, AWS...) plusieurs options/services pour l’hébergement des applications. On peut les qualifier de plus ou moins “cloud”, selon qu’ils ont une approche classique proche des pratiques d’hébergement habituelles où la machine et l’OS font partie intégrante de l’offre (serveurs dédiés, machines virtuelles - il incombe au client ou à l’infogérant de configurer l’OS), ou au contraire s’ils font totalement abstraction de la machine et de l’OS sous-jacents.
Selon l’offre d’hébergement que l’on cible, les impacts et les modifications à apporter à une application .NET, afin de la porter dans un environnement cloud, sont très différents.
Commençons tout d’abord par la présentation des offres d’hébergement cloud, et je vous présenterai ensuite en détail les impacts pour déployer une solution .NET classique dans un environnement cloud. Le déploiement que je prends en exemple porte sur une solution e-commerce Cloud Commerce factory (http://www.cloudcommercefactory.com/) qui contient plusieurs applications web ASP.NET MVC 4, ainsi qu’un service Windows.
Ce document n’est pas une revue exhaustive des options offertes par le cloud, mais plutôt un compte rendu d’expérience de déploiement au cours de laquelle j’ai essayé de trouver un compromis entre déploiement 100% cloud et des modifications raisonnables apportées à la solution.
Par ailleurs, je ne détaille pas les opérations de déploiement, ni d’automatisation de ce dernier, qui font l’objet d’un autre article.
Services d’hébergement Windows Azure
Si l’on
prend le cas spécifique de Windows Azure (la plateforme cloud que je connais le
mieux), voici les quatre différentes offres disponibles pour l’hébergement
d’une application web ou de type service/daemon.
Machine virtuelle
Pas trop cloud, c’est un OS complet virtualisé. Il est intéressant lorsque l’on a besoin d’un accès bas niveau à l’OS, mais il a aussi beaucoup d’inconvénients - long à déployer et à démarrer, long à répliquer (l’image est lourde, car elle contient un OS complet), nécessité de gérer les backups. C’est l’héritier direct des serveurs dédiés que l’on connaît depuis des années. On a la liberté totale sur l’OS: gestion des ports, installation d’applications et binaires de notre choix.
A noter que Windows Azure propose un grand nombre de distributions autres que Windows Server, aussi bien en natif que via la marketplace Azure. On peut ainsi installer un Ubuntu, une Red Hat, une distribution Hortonworks pour faire du Hadoop, mais aussi des OS déjà packagés avec des applications comme un package LAMP ou un LAMP+Joomla.
Le point d’entrée lors du déploiement d’une machine virtuelle est bien l’OS. On
le manipule explicitement, on le paramètre, et on doit avoir les compétences
pour le faire. En l’occurrence ce service est le même que celui offert par des
dizaines d’autres hébergeurs spécialisés dans les machines virtuelles, à la
différence près qu’il permet de bénéficier de l’écosystème Azure.
Cloud Service
Ce sont également des machines virtuelles, un peu plus cloud, mais pas encore totalement. La définition des cloud services nous explique que “La priorité est donnée aux applications, pas au matériel”. Ce n’est pas très clair, voici comment je définirais les cloud services avec mes propres termes. Le point de départ est l’application. Lorsque l’on demande son déploiement dans un cloud service, pas besoin de créer préalablement une machine virtuelle. Windows Azure la crée pour vous à la volée. On a dès lors accès :
- A l’OS,
- Au système de fichiers,
- Au serveur web le cas échéant,
- Au bureau à distance,
- A un certain nombre de paramètres de l’OS, définis dans le fichier de configuration du package. On peut par exemple ouvrir des ports entrants autres que les 80 et 443, pour communiquer soit vers le monde extérieur, soit vers d’autres composants d’une architecture cloud.
Il ne faut pas toutefois trop s’attacher à l’OS, car la machine virtuelle peut être détruite et recréée. L’important est le package applicatif, et pas le système d’exploitation qui l’héberge. Les cloud service sont dès lors bien taillés pour la réplication (car le package peut être déployé à volonté, sans aucune intervention manuelle), mais étant stateless il ne faut pas persister de données importantes (uniquement des données temporaires) sur leur file system, ni les utiliser pour héberger une base de données.
Aussi bien pour les machines virtuelles que pour les cloud services, on parle
de IaaS: Infrastructure as a Service. Aussi bien pour les machines virtuelles,
que pour les cloud services, le développeur n’est pas tellement incité à
découper sa solution en micro-services. Les micro-services offrent plus de
souplesse et une meilleure granularité lorsque se présente le besoin de scaler
/ échelonner les différents services de sa plateforme (front web, API, base de
données, cache) pour répondre à des pics ou à une croissance de la charge.
Voilà enfin du 100% cloud pour l’hébergement de votre application web. Le point d’entrée d’un déploiement cloud est l’applicatif. Cette fois, plus aucune interaction avec l’OS… On ne sait même pas vraiment explicitement quelle est la plateforme sous-jacente (sans doute un IIS).
Le déploiement est très rapide, ainsi que la réplication. 4 possibilités permettent d'interagir avec son app service :- Le portal web Windows Azure, en mode clic,
- Le Azure CLI - les outils clients en ligne de commande,
- Visual Studio,
- Azure Resource Manager + Powershell - je détaille cette méthode dans un prochain article.
Les App Services offrent une solution qui permet également d’exécuter des jobs en
tâches de fond. Les jobs peuvent être soit planifiés, soit exécutés à la
demande.
Comme l’indique cet article d’introduction,
le service est très souple sur le format de l’exécutable. Vous pouvez
télécharger et exécuter un fichier exécutable comme cmd, bat, exe (.NET), ps1,
sh, php, py, js et jar.
Le SDK azure Web Jobs offre par ailleurs un certain nombre de fonctionnalités supplémentaires, aussi bien au sein des webjobs que vous développez, que pour monitorer leur exécution :
- Déclencher une méthode à chaque fois qu’un éléments est inséré dans une file d’attente, un blob, un service bus,
- Déclencher une méthode à chaque fois qu’un élément est modifié dans un blob,
- Déclencher l’exécution d’un job depuis une autre application,
- Pour la
vue d’ensemble: voir ici
Docker
Docker est un service de conteneur basé sur Linux. L’approche consiste à livrer
un conteneur qui contient aussi bien l’applicatif, qu’une version réduite du
file system Linux, et les dépendances de l’application : un serveur web (Apache,
NGinx…), une base de données, un système de cache...
En ce qui concerne Docker, c’est un sujet encore relativement nouveau dans
l’univers .NET mais cela va bien changer dans les mois à venir. Pour héberger
son applicatif dans un conteneur Docker, il faut que l’applicatif soit
hébergeable sur Linux et cela n’était possible jusqu'à maintenant qu’avec Mono.
Toutefois l’arrivée en version 1.0 du Core CLR va offrir, en plus des
conteneurs Windows Server prévus pour l’été 2016, une option supplémentaire.
Impacts lors d’un déploiement avec app services et
cloud services
Base de données
Utilisez-vous une base de données relationnelle ? Un SQL Server par exemple ? Si oui vous voudrez sans doute migrer votre base de données vers un service SQL Database, qui est en fait une version cloud de SQL Server Standard, avec quelques limitations.
Concernant les autres types de bases de données, je ne les ai pas testés. Mais après quelques recherches, les services proposés sur Azure semblent entièrement basés sur les versions standard : MongoDB Enterprise Edition, MySQL Commmunity Edition pour n’en citer que quelques uns.
Afin d’identifier si votre base de données est compatible en l’état pour une migration vers SQL Database, utilisez l’outil SQL Azure Migration Wizard. L’outil est disponible sur Codeplex à cette adresse. L’outil permet:
- D'analyser votre base de données, et d'identifier dans un rapport les éventuelles incompatibilités de votre base de données avec SQL Database,
- De générer des scripts de création de votre base de données : tables, indexes, procédures stockées, contraintes…
- De générer des fichiers d’export de vos données avec l’utilitaire BCP,
- De se connecter à votre compte Azure et à votre service SQL Database, afin d’exécuter l’ensemble des scripts et effectuer l’import des données
Quelles sont les limitations de SQL Database qui pourraient vous forcer à revoir l’architecture de votre base de données ? A ma connaissance il n’y en a pas beaucoup, en voici quelques unes:
- Assemblies C# intégrées à SQL Server - peu utilisé à ma connaissance, et maintenant totalement supplanté par les ORMs côté applicatif (Entity Framework, NHibernate) qui permettent de manipuler les données en LINQ
- Jobs via SQL Agent
- Authentification Windows
- Connexions autres que TCP/IP - named pipes par exemple
La liste des limitations est visible à cette adresse.
Si vous n’utilisez aucune des ces fonctionnalités, SQL Azure Migration Wizard
générera non seulement les scripts, mais effectuera également le déploiement
vers Azure !
- Lancez SQL Azure Migration Wizard, et sélectionnez “Analyser et migrer” → “Base de données”
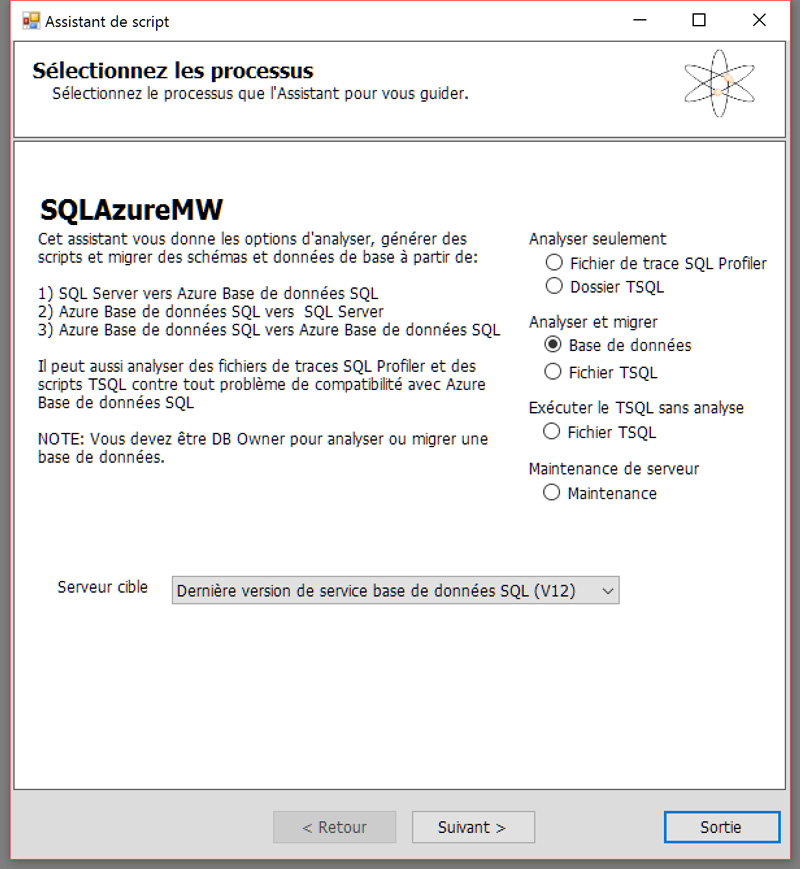
- Renseignez le nom de la BDD, le nom de l’hôte et les informations de connexion, puis à l’étape suivante sélectionnez la BDD. Conservez le choix “Scripter tous les objets de la base de données”
- A l’étape suivante, validez le résumé, puis démarrez l’analyse et l’export. Une fois le traitement effectué, sélectionnez “sauvegarder” afin d’exporter le rapport d’analyse. Ce sera beaucoup plus pratique pour le lire. Vous pouvez également enregistrer le script d’export de votre base de données, en cliquant sur l’onglet “Script SQL”.

- Ouvrez le rapport, et les incompatibilités sont alors très faciles à identifier puisqu’écrites en rouge. En ce qui me concerne, la seule compatibilité identifiés porte sur l’une des procédures stockées aspnet_xxxx pour la gestion des utilisateurs, des rôles et des profils. Et c’est une chance car ce n’est pas une procédure stockée utilisée par la solution:
StoredProcedure
[dbo].[aspnet_Setup_RemoveAllRoleMembers] -- sp_helpuser is not supported in
current version of Azure SQL Database.
Si vous avez
également de la chance, les incompatibilités s’arrêtent là et vous n’avez donc
pas de modifications à apporter à votre modèle de données / procédures
stockées.
Je vous invite également à regarder dans le répertoire “C:SQLAzureMWBCPData”,
dans lequel vous pourrez trouver l’export de vos données effectué avec l’outil
BCP. Ces données associées au script généré en dernière étape vous permettent
d’exporter 100% de votre base de données en un minimum d’étapes.
Comme je déteste faire les choses à moitié, je m’étais fixé comme objectif de déployer les applications web dans App Services, soit le service le “plus cloud” d’hébergement d'Azure, entièrement gérable par le biais du portail Azure, d'APIs REST ou en ligne de commande (Azure CLI).
Si vous ciblez un déploiement dans une VM, ou dans cloud service, les impacts seront faibles voire nuls car ces deux solutions sont respectivement équivalentes et proches d’un hébergement classique.
Dans le cas de votre application web, les impacts dépendent fortement de votre architecture. Une remarque un peu générale: il est beaucoup plus facile de substituer au cas par cas des composants/modules de votre application si vous avez généralisé l’utilisation de l’injection de dépendance. J’utilise pour ma part StructureMap, qui permet aussi bien de faire de l’injection que de gérer finement le cycle de vie (singleton, requête, thread…) de chacun des objets.
File SystemApps Services offre à votre application une vision très restreinte du file system, réduite à sa propre arborescence. Celle-ci est par ailleurs isolée. Ainsi, si votre application dans app services peut utiliser le file system en lecture et en écriture (persistence de ressources de type images, fichiers de logs…).
C’est à ce niveau que j’ai eu à gérer le plus d’impacts.
Mais la limitation va se poser si vous cherchez à partager des fichiers entre
vos différentes applications web et services. Il va dès lors falloir envisager
d’utiliser un service de stockage Azure. Les comptes de stockage et comptes de
stockage classiques offrent plusieurs services très différents les uns des
autres :
- Objets blob: stockage d’objets binaires, fichiers. Relativement similaire aux fichiers (à ma connaissance). Permet également de générer des tokens d’accès temporaires par fichier pour le partage en REST.
- Tables: base de données NoSQL orientée documents. A voir l’intérêt par rapport aux autres produits du marché également disponibles dans le cloud (Mongo DB, Couchbase)... D’autant plus que si votre application intègre déjà l’une de ces solutions, il n’y a pas vraiment d’intérêt à implémenter un client différent.
- Files d’attente: l’équivalent de MSMQ dans le cloud, nécessite également d’utiliser l’API spécifique pour les exploiter. Les files d’attente permettent de découpler 2 composants de votre application.
- Fichiers (ce qui nous intéresse): service de file system, avec plusieurs APIs pour y accéder. Plus de détails ci-desous.
Important: il n’y a pas de différence fondamentale entre les comptes de
stockage, et les comptes de stockage classiques. Essentiellement les APIs qui
permettent de les utiliser.
Je vous invite à lire cette page de documentation au sujet du service destockage/fichiers. Si vous n’en avez pas le courage, voici quelques remarques :
- Le service de fichiers peut être monté comme un dossier partagé classique. Aussi bien depuis une machine virtuelle Azure, que depuis votre poste de développement sous réserve que les ports soient ouverts. Mais malheureusement, les app services ne permettent pas de monter un partage réseau.
- On peut manipuler le service de fichiers via Azure CLI (lignes de commande powershell): création des conteneurs, manipulation des répertoires et des fichiers.
- Il existe également une API .NET qui vous permet de manipuler le service de fichiers depuis votre application.
Les étapes:
- Créer le service de stockage - vous pouvez également utiliser le storage emulator en local sur votre machine, lors de vos développements.
- Comme indiqué plus haut, l’utilisation de l’injection de dépendance est généralisée dans l’application. Aucun des composants n’écrit directement sur le file system. Ils se voient plutôt injecter une implémentation de l’interface “IFileStorageProvider”, faisant l’abstraction avec le support de stockage sous-jacent.
namespace
MPf.Core.StorageProvider
{
public interface
IFileStorageProvider
{
void
FileWrite(String filePath, byte[] data);
Boolean
FileExists(String filePath);
byte[]
FileRead(String filePath);
void
FileDelete(String filePath);
void
FileMove(String origFilePath, String filePath);
Boolean
DirectoryExists(String directoryPath);
void
DirectoryCreate(String directoryPath);
String[]
DirectoryGetFiles(String directoryPath, String fileName);
}
}
- Jusque là, la seule implémentation était un classique FileSystemStorage, destiné à écrire sur le file system local. J’ai créé une seconde implémentation AzureFileStorage (sources ci-joint). Vous remarquerez l’utilisation de CloudConfigurationManager.GetSetting qui permet aussi bien de lire dans le web.config traditionnel, que dans les paramètres définis spécifiquement dans App services, lors du déploiement (ces derniers overrident/prennent le pas sur le web.config).
public
AzureFileStorage(String shareName)
{
String
connectionString = CloudConfigurationManager.GetSetting("AzureFileStorageResourcesConnectionString");
storageAccount
= CloudStorageAccount.Parse(connectionString);
fileClient
= storageAccount.CreateCloudFileClient();
share
= fileClient.GetShareReference(shareName);
if
(!share.Exists())
share.Create();
rootDir
= share.GetRootDirectoryReference();
}
- Enfin, au démarrage de l’application, StructureMap nous permet d’injecter la bonne dépendance en fonction de l’environnement. FileSystemStorage si on est dans un environnement serveur standard, AzureFileStorage en environnement cloud. La logique est très simple, et est basée sur la présence ou non d’une chaîne de connexion Azure Storage dans le fichier de config.
//Hosted on
Azure or IIS ?
For<MPf.Core.StorageProvider.IFileStorageProvider>().Use(c
=>
{
if
(String.IsNullOrEmpty(System.Configuration.ConfigurationManager.AppSettings["AzureFileStorageResourcesConnectionString"])
&&
System.Configuration.ConfigurationManager.ConnectionStrings["AzureFileStorageResourcesConnectionString"]
== null)
return
c.GetInstance<StorageProvider.FileSystemStorage>(); //On définit le
FileSystemStorage (utilise le file system classique) comme implémentation par
défaut lorsque la chaîne de connexion Azure Storage n’est pas présente dans le
fichier config
return
new StorageProvider.AzureFileStorage("resources"); //Autrement, on
définit le AzureFileStorage comme implémentation par défaut
});
Logs
Pas d’impact si vous les stockez dans l’arborescence de l’application. Mais ce n’est pas forcément la façon idéale, car ils ne seront pas très pratiques à consulter.
J’utilise pour ma part du log fichier, conjointement avec une solution SaaS en ligne (Aibrake) qui me permet d’avoir des alertes et de consulter les logs sans accéder aux fichiers.
Azure propose une solution appelée Application Insights, que je n’ai pas encore testée. Elle semble toutefois très similaire aux solutions du marché comme App Dynamics.
Remarque importante : dans le cas où vous indiqueriez les chemins des logs avec des chemins absolus, il faudra évidemment les changer en chemins relatifs afin de stocker les logs dans l’arborescence de l’application, et prendre soin de bloquer l’accès au répertoire avec un web.config adapté.
Autres points importants/bloquants
Utilisez-vous
des binaires/exécutables côté serveur ? Ce point peut être bloquant pour un
hébergement dans une approche web app et vous oblige à opter pour une machine virtuelle ou
un cloud service.
La solution déployée intègre un .exe installé sous forme de service Windows. Il intègre son propre planificateur de tâches basé sur Quartz.NET, et tourne en permanence en effectuant des tâches telles que :
- Traitement en masse de catalogues produits,
- Notifications par email,
- Mise à jour de statuts de commandes,
- Extensible à tout type de tâche que l’on souhaite exécuter en asynchrone.
Un point important : le service ouvre un socket, auquel se connectent les
applications web pour lui envoyer des instructions de gestion des jobs (démarrer un job, planifier un nouveau job, supprimer un job).
Web jobs
Les Web jobs auraient pu à priori se prêter à l’hébergement du .exe, si ce n’est qu’ils ne permettent pas d’ouvrir des ports entrant. Il aurait donc fallu faire communiquer les Web apps et le .exe d’une manière différente (via file d’attente, service bus...) et la volonté de ne pas refondre une partie aussi importante de l’application m’a poussé à envisager une autre solution.
Cloud Service
J’ai donc opté pour l’hébergement dans un Cloud service. Les applications
web et le service partagent un grand nombre de composants, et les développements
effectués précédemment pour la gestion des fichiers via le compte de stockage
font qu’il n’y a pas d’autres impacts sur l’applicatif.
Je fais donc ici le choix du compromis, et nous détaillerons les étapes de
configuration de l’environnement et de déploiement dans un prochain article.
Par ailleurs, ce compromis n’a pas vraiment d’incidence dans mon cas, car il
n’est pas prévu de scaler le service. En effet, l’applicatif fait qu’il ne peut
y avoir qu’une seule instance du service à l’instant T (en contrepartie les
traitements sont parallélisés au sein de l’instance). C’est donc sur ce constat
que je clôture ce chapitre: les déploiements cloud sont toujours à considérer
en fonction de l’applicatif et du projet dans sa globalité (charge/trafic
prévisibles, nécessité de pouvoir upscaler et downscaler rapidement...).
Note de fin
Comme vous pouvez le constater, dans mon cas, les impacts ont été relativement limités. Tout dépend des fonctionnalités SQL Server utilisées, et également de la façon donc votre application est architecturée, l’injection de dépendance apportant beaucoup de souplesse.
N’hésitez pas également à me faire vos retours d’expérience à ce sujet, et à m’indiquer si vous avez rencontré d’autres impacts.
Vous
retrouverez dans un prochain article le détail d'un déploiement via Azure
Resource Manager (description de l'environnement et du déploiement avec des
templates JSON) + Powershell.