
Agents IA : les sites web se mettent à jour


Selon le rapport 2026 sur l'état du trafic IA et des cybermenaces, le trafic généré par les agents IA et les navigateurs agentiques a connu une croissance de près de 8 000% depuis l’an passé. On pense à l’arrivée de "Comet" de Perplexity, "Fellou", "Genspark AI Browser" ou "Neon" d’Opera. Ces agents ne se contentent plus de lire du contenu. Selon cette même enquête, 77% de leur activité se concentre sur les pages de produits et de recherche. Et plus de 2% atteignent les flux de paiement.
Les agents IA souvent en difficulté pour analyser les sites Web
Pour aider les agents à trouver et à utiliser les propriétés web, des stratégies se font jour. "Nous sommes en train de passer d'un web conçu pour les navigateurs à un web conçu pour les agents", présente Vincent Terrasi, cofondateur de Draft & Goal. "Les sites qui anticipent cette transition auront un avantage structurel."
Or, la première chose à comprendre, selon lui, est que le web n'a pas été conçu pour les machines. "Le HTML est un format de présentation visuelle. Quand un agent IA analyse une page web aujourd'hui, il doit traverser du HTML, CSS et JavaScript, tout ce qui sert à l'affichage mais qui n'a aucune valeur sémantique pour une IA. C'est coûteux en tokens, lent, et cela gaspille de l'énergie."
Trois degrés d’ouverture aux agents IA
Afin de bien accueillir les agents IA sur son site web, Vincent Terrasi distingue différents niveaux de maturité. Le premier, la "base", est d’ouvrir son robots.txt aux crawlers IA (GPTBot, ClaudeBot, PerplexityBot), structurer ses données avec Schema.org, et s'assurer que le contenu est accessible, sans exécuter du JavaScript. "C'est le minimum", cingle l’expert en IA. "Cela ne différencie personne, mais sans cela, un site est invisible pour les agents."
Le niveau deux est de penser "machine-readable first". "Cela veut dire : proposer une version IA avec un contenu important et une FAQ balisée", pense Vincent Terrasi "Parce que les paires question-réponse sont exactement le format que les LLM exploitent le mieux."
Le troisième niveau doit amener à repenser la couche de communication entre un site web et un agent IA. "Aujourd'hui, il n'existe aucun standard W3C (World Wide Web Consortium) ou IETF (Internet Engineering Task Force). Mais je suis de près le WebMCP (Web Model Context Protocol).", prévient Vicent Terrasi. Notons que, selon Google, le WebMCP "vise à fournir une méthode standard pour exposer des outils structurés, en veillant à ce que les agents d'IA puissent effectuer des actions sur votre site avec plus de rapidité, de fiabilité et de précision." On pense aussi au MCP (Model Context Protocol) d'Anthropic, à l'AP2 (Agent Payments Protocol), à l'ACP (Agent Communication Protocol), le protocole d'IBM/BeeAI pour la communication inter-agents, ou à l'A2A (Agent to Agent), la spécification open source de Google pour standardiser la communication entre agents IA.
"Nous sommes dans une phase où chaque acteur comme OpenAI, Anthropic, Google définit ses propres règles d'interaction avec le web", analyse Vincent Terrasi. "C'est comparable aux débuts du web où chaque navigateur interprétait le HTML différemment. Un consensus va émerger, mais nous n’y sommes pas encore. Et les sites qui investissent aujourd'hui prennent le risque de devoir s'adapter si le standard final diffère de ce qu'ils ont implémenté."
Un DOM revu pour les IA
De son côté, Vincent Terrasi et les équipes R&D de Draft & Goal ont breveté le protocole GibberDOM. La solution doit transformer un document HTML en une représentation intermédiaire optimisée qui guide l'agent dans sa navigation. GibberDOM doit empêcher pour cela que l'agent IA trouve sur le site web des éléments classiques du DOM, comme les balises de style, les scripts, les attributs visuels, les publicités et les menus redondants. Autant d'éléments dont il ne se sert pas. Rappelons en effet que le DOM (pour Document Object Model) transforme le texte d'une page web en un "arbre". Avec lui, chaque élément (titre, image, bouton) devient un objet que l'on peut manipuler."C’est un format de compression qui transforme toutes les connaissances autour de plusieurs pages HTML en un DOM optimisé pour les agents IA", pointe Vincent Terrasi.
D’après Vincent Terrasi, le résultat du DOM optimisé est une réduction de 60 à 70% du nombre de tokens consommés par le LLM. Le tout en préservant l'intégralité de la sémantique de toutes les connaissances. "Et l'agent n'a plus besoin de crawler le site page par page : toutes les données arrivent en un seul appel, dans le format qu'il demande." Cela doit amener une latence divisée et des coûts d'API LLM réduits de moitié. Et une qualité de réponse supérieure, parce que l'agent travaille sur des données sémantiquement structurées plutôt que sur du HTML qu'il doit deviner.
"Prenons un média IA qui nous sert de plateforme de tests comme PleaseTrip.com. Un site de planification de voyage qui propose des données météo sur 12 mois pour des centaines de destinations", lance Vincent Terrasi. "Aujourd'hui, un agent IA qui veut comparer 30 destinations pour un voyage en janvier doit crawler 30 pages, analyser le HTML de chacune, extraire les données météo du balisage visuel. Avec GibberDOM, l'agent reçoit l'ensemble des données structurées, avec les destinations, les mois optimaux, les types de climat, les équipements recommandés en un seul appel compressé. Nous passons de 30 requêtes HTTP, avec du HTML "verbeux", à un appel avec une réduction de 60 à 70% des tokens. Le site a d'ailleurs déjà franchi une première étape en déployant un serveur WebMCP qui expose ses données via des outils structurés pour les agents. C'est exactement la bonne direction."
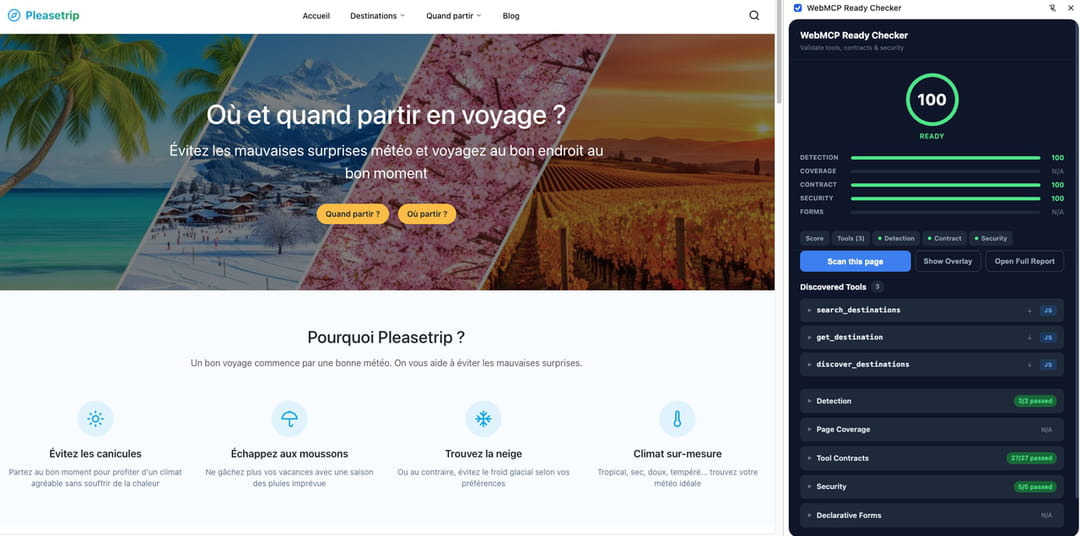
Le contrôle et la sécurité en question
Cependant, Vincent Terrasi sait qu’accueillir des agents IA sur un site web comporte de forts risques. D’abord au niveau du contrôle. "Ouvrir son site aux agents IA, c'est accepter que du contenu soit consommé, reformulé et redistribué par des systèmes qu'on ne maîtrise pas", souffle-t-il. "Une partie significative de ce trafic provient hélas de bots malveillants."
Également, la sécurité reste un sujet important. "À partir du moment où on sert du contenu structuré à des agents autonomes, on crée une surface d'attaque." Le prompt injection, soit le fait d’injecter des instructions malveillantes dans du contenu qu'un agent va traiter, est un risque documenté. Microsoft a publié récemment sur le sujet. "Et dans les architectures multi-agents, un seul agent compromis peut contaminer 87% des décisions en aval en moins de 4 heures", reprend Vincent Terrasi. Il assure que GibberDOM intègre une signature cryptographique dans chaque document transmis pour garantir l'authenticité et l'intégrité des données que l'agent consomme. "Mais c'est un problème systémique. La majorité des déploiements d'agents en production aujourd'hui n'ont pas de validation sécurité complète."