
Secrets dans le code source : pourquoi le stockage des secrets dans Git pose-t-il problème ?

Bien que les secrets tels que les clés API, les jetons OAuth, les certificats et les mots de passe soient extrêmement sensibles, il est fréquent qu'ils se retrouvent dans le code source présent dans des dépôts git. Pourquoi ce phénomène et comment l'éviter ?
Trouver des secrets dans les systèmes de contrôle de version (VCS) comme Git est malheureusement très fréquent bien que ce soit considéré comme une mauvaise pratique. Une fois que le code source est poussé dans un dépôt Git, il peut organiquement se diffuser dans de multiples endroits. En incluant tous les secrets qui peuvent s’y trouver. Mais alors pourquoi trouver des secrets dans les dépôts git est-il si courant ?
Pourquoi les secrets finissent-ils dans Git ?
Un développeur expérimenté se demandera sûrement pourquoi quelqu'un pourrait mettre des secrets dans un dépôt Git. Mais le fait est que des secrets s’y retrouvent bel et bien.
Dans mon article précédent, j’expliquais qu'il est courant de choisir la voie de la moindre résistance pour accéder à des secrets et les distribuer. Git agit comme le point central pour un projet, il est donc logique, au moins d'un point de vue pratique, que les secrets soient stockés dans un dépôt Git privé pour en faciliter la distribution et l'accès.
Mais stocker des secrets de cette manière, c'est jouer avec le feu : un simple incident peut mener à un vrai problème de sécurité.
De plus, lorsque les secrets ne sont pas gérés correctement, il est très facile d'en perdre la trace. Les secrets peuvent être codés en dur dans le code source, stockés dans un fichier texte, partagés sur Slack ou enfouis dans un log d'application de débogage. Les développeurs peuvent se trouver dans de grandes équipes distribuées ayant accès à pléthore de secrets, tout en étant soumis à des cycles de release rapides et devant maîtriser un nombre toujours croissant de technologies. Un environnement propice aux erreurs.
Pourquoi est-il dangereux de stocker des secrets dans Git ?
Il faut rappeler que le code source est par nature très propice à la diffusion. Le code est copié et transféré partout. Git est conçu de manière à permettre, voire à promouvoir, la libre distribution du code.
Les projets peuvent être clonés sur plusieurs machines, forkés vers de nouveaux projets, distribués à des clients, rendus publics, etc. Chaque fois qu'il est dupliqué sur Git, l'historique complet de ce projet est également dupliqué.
La raison pour laquelle le stockage de secrets dans des dépôts publics est une très mauvaise pratique est évidente. Ils deviennent totalement disponibles pour tout le monde sur internet et il est très facile de surveiller les dépôts publics. En effet, GitHub dispose d’une API publique permettant de récupérer tous les commits publics.
Mais qu'en est-il des dépôts Git privés ?
Les dépôts privés ne publient pas ouvertement votre code source sur Internet, mais ils ne disposent pas non plus d'une protection adéquate pour stocker des informations aussi sensibles. Imaginez qu'il y ait un fichier texte contenant tous vos numéros de carte de crédit : vous ne le placeriez certainement pas dans le dépôt Git de l'entreprise. Il se trouve que les secrets sont tout aussi sensibles.
Quelques éléments à prendre en compte lors du stockage de secrets dans des dépôts privés :
- Toute personne de l'organisation ayant accès au dépôt a accès aux secrets qu'il contient (un seul compte compromis peut permettre à un attaquant d'accéder à une multitude de secrets).
- Les référentiels peuvent être clonés sur plusieurs machines ou forkés vers de nouveaux projets.
- Des dépôts privés peuvent être rendus publics, et avoir des secrets enfouis dans l'historique Git.
Une autre considération importante : le code supprimé d'un dépôt Git ne disparaît jamais réellement.
Git garde la trace de toutes les modifications apportées. Le code qui est supprimé existe toujours dans l'historique de Git.
Il est intéressant de noter que le code supprimé d'un projet correspond à peu près au volume de code qui y est ajouté. Concrètement, on ne voit que la partie immergée de l’iceberg : des secrets pourraient être loin sous la surface, dans l'historique Git, sous une masse de commits qui ont été oubliés depuis longtemps.
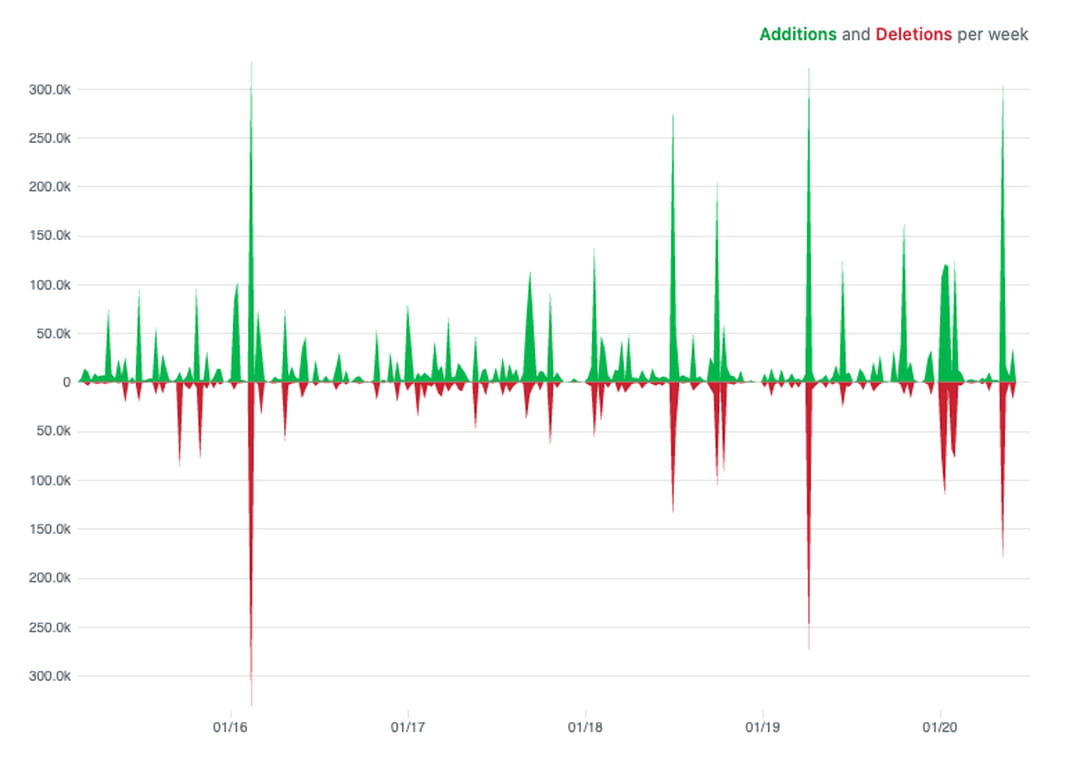
Le graphique des contributions ci-dessus, issu du dépôt HashiCorp Vault, est une vue typique de l'historique d'un projet. La régularité que l'on trouve dans les graphiques de contributions aux projets est à la fois surprenante et intéressante (regardez les graphiques d’autres projets, il semble y avoir une règle immuable).
Exemples concrets : des cas récents de fuites de données
Les fuites de secrets dans des repos publics se produisent avec une régularité surprenante.
Si vous effectuez une recherche sur GitHub pour le message commit "removed aws key", vous trouverez des milliers de résultats. Et ce, uniquement dans les dépôts publics.
GitGuardian détecte plus de 3 000 secrets chaque jour, rien que sur GitHub public. Il y en a des milliers, mais vous trouverez ci-dessous quelques exemples récents ou dignes d'intérêt.
Exemples publiquement divulgués de fuites de données récentes dues à des fuites de secrets :
- Fuite de données chez Starbucks - janvier 2020
- Clé API JumpCloud trouvée dans un dépôt GitHub.
- Fuite de données d'Equifax - avril 2020
- Des secrets divulgués dans un compte GitHub personnel ont donné accès à des données sensibles de clients d'Equifax.
- Fuite de données chez Uber - octobre 2016
- Une mauvaise hygiène des mots de passe a permis à des intrus d'accéder au Datastore Amazon S3 d'Uber en utilisant une clé d'accès AWS publiée dans un dépôt GitHub privé.
- Fuite de données aux Nations Unies - Janvier 2021
- .gitcredentials dans un dépôt de code public permettant l'accès à des dépôts privés contenant de l'information sensible.
Ce problème ne concerne pas uniquement les grandes entreprises. Les attaquants exploitent constamment des services à l’aide de clés individuelles qui ont fuitées. Par exemple, des acteurs malveillants ont scanné GitHub à la recherche de clés AWS et les ont utilisées pour miner de la cryptocurrency, laissant les développeurs avec des milliers de dollars de dettes.
Détecter les secrets pendant les revues de code (ou pas)
Un grand avantage de git est de pouvoir voir rapidement et clairement les modifications apportées, et de comparer le code avant et après la modification. Il est donc courant de croire que si des secrets sont divulgués dans le code source, ils seront bien sûr détectés lors d'une revue de code ou dans une pull request.
Les revues de code sont très utiles pour détecter les défauts de logique, maintenir de bonnes pratiques de codage et préserver la qualité du code. Mais elles ne constituent pas une protection adéquate pour détecter les secrets.
En effet, les revues ne prennent généralement en compte que la différence nette entre l'état actuel et les modifications proposées. Elles ne prennent pas en compte l'historique complet d'une branche. Les branches sont généralement nettoyées avant d'être fusionnées dans la branche principale. Du code temporaire est ajouté puis supprimé, des fichiers inutiles ajoutés puis supprimés... Mais maintenant ces fichiers, qui sont des candidats à haut risque pour contenir des secrets, ne sont pas visibles pour celui qui revoit le code (à moins qu'il ne veuille parcourir l'historique complet d'une branche).
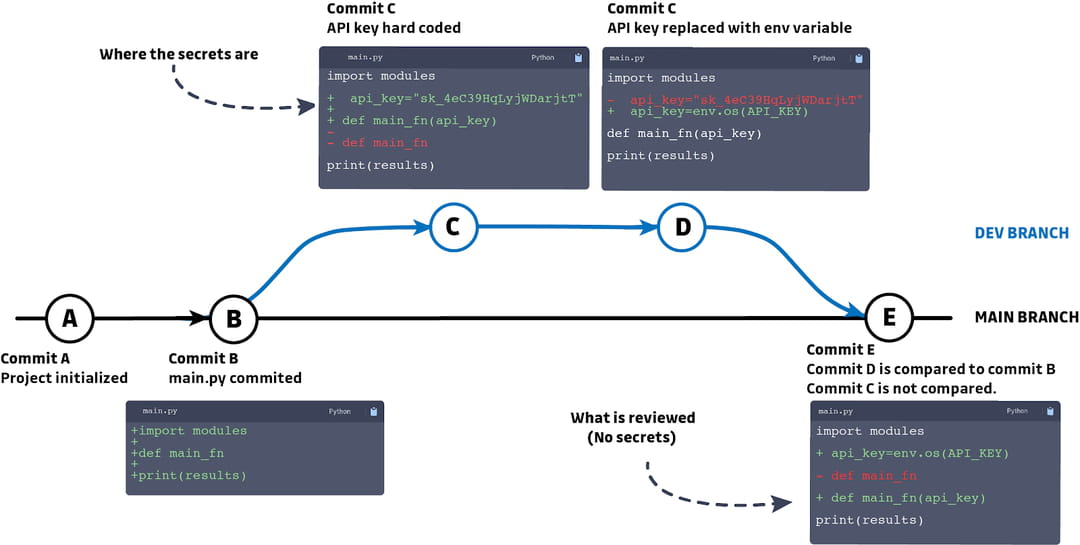
Reprenons l'exemple ci-dessus. Bien qu'il soit simplifié à l'extrême, il raconte une histoire familière.
Dans le commit B, un fichier nommé main.py est ajouté. Une nouvelle branche est créée pour ajouter une nouvelle fonction à main.py dans le commit C. Cette fonctionnalité utilise une clé d’API, donc pour gagner du temps lors des tests, elle est codée en dur. Une fois les tests validés, la clé d’API codée en dur est remplacée par une variable env et le fichier est nettoyé. Enfin, une pull request est faite et acceptée parce que la revue de code prend en compte la différence nette entre le commit B et D, ignorant le commit C. Maintenant, des secrets non détectés sont enfouis dans l'historique Git du projet.
Bien que ce scénario soit très basique, ajoutez des centaines de commits et de fichiers entre le master et une branche de développement et vous pouvez voir à quel point il est facile de manquer des secrets dans les revues de code.
Utiliser la détection automatique pour trouver des secrets dans Git
Si l'on considère tout ce que nous venons de dire sur les secrets dans Git, il est clair que ce problème va persister et que nous ne pourrons pas le résoudre avec des revues de code manuelles. Bien que l'automatisation ne soit pas toujours la solution, la détection des secrets, et en particulier des secrets dans Git, est une solution claire à ce problème courant.
Malheureusement, la détection des secrets dans Git n'est pas aussi facile qu'il n'y paraît en raison de la nature probabiliste des secrets. Il est donc difficile de faire la distinction entre un véritable secret et d'autres chaînes de caractères d'apparence aléatoire comme les identifiants de bases de données ou d'autres hachages.
La bonne nouvelle, cependant, est qu’il existe des outils puissants pour les développeurs afin de détecter les secrets dans Git.
Récapitulons
Faisons un rapide bilan de ce que nous avons vu. Les dépôts Git sont des endroits très courants pour trouver des secrets et ils restent l'incubateur parfait pour que les secrets se diffusent à plusieurs endroits. Git garde une trace de l'historique d'un projet, ce qui rend la recherche de secrets difficile. En raison de la manière dont le protocole Git est utilisé, il est courant que des secrets ne soient pas détectés lors des revues de code manuelles. Pour ces raisons, la détection automatique des secrets devrait être introduite dans le cycle de vie du développement logiciel.