
PyTorch : tout savoir sur la bibliothèque de deep learning

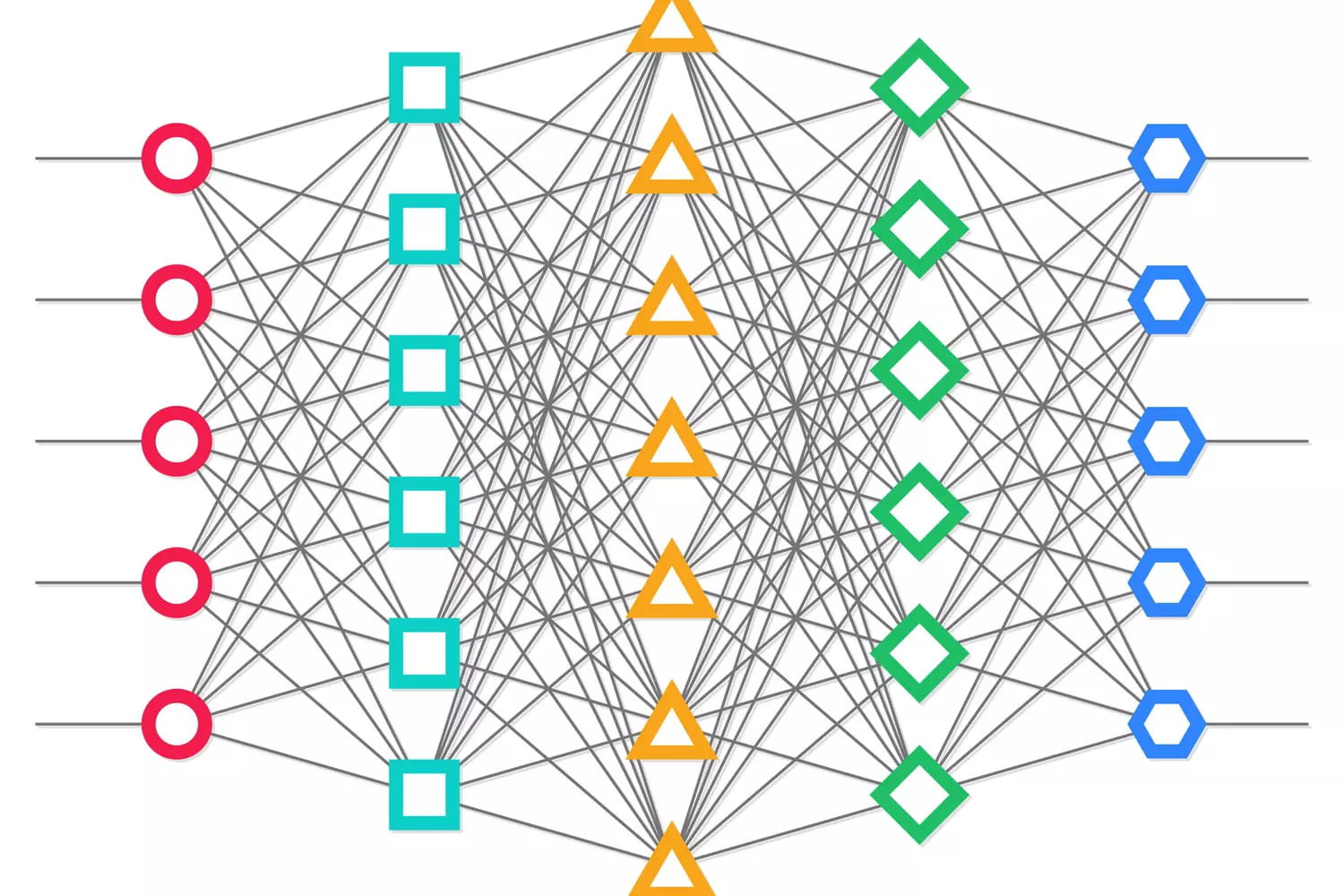
PyTorch, c'est quoi ?
PyTorch est une bibliothèque d'IA, développée par Meta (ex-Facebook), écrite en Python pour se lancer dans le deep learning (ou apprentissage profond) et le développement de réseaux de neurones artificiels. À partir de plusieurs variables, elle peut servir à réaliser des calculs de gradients ou à utiliser des tableaux multidimensionnels obtenus grâce à des tenseurs.
PyTorch est disponible depuis 2016 en open source sous licence BSD Modifiée. En 2018, la librairie est fusionnée par Meta avec Caffe2, son infrastructure de deep learning taillée pour les déploiements et capable de prendre en charge des algorithmes d'apprentissage ingérant jusqu'à des dizaines de milliards de paramètres.
En septembre 2022, Meta annonce la création d'une fondation qui sera en charge du projet : la PyTorch Foundation. Une organisation indépendante qui est placée sous l'égide de la fondation Linux. Son comité de direction est composé de représentants d'Amazon Web Services, d'AMD, Google Cloud, Meta, Microsoft Azure et Nvidia...
Comment télécharger PyTorch ?
Pour télécharger PyTorch, il suffit de se rendre sur la page officielle du projet sur GitHub et de sélectionner le fichier via l’onglet "Code". Des extensions sont également accessibles ici.
Comment installer PyTorch ?
Pour les systèmes d’exploitation Windows, Linux et macOS, PyTorch peut être installé depuis le gestionnaire de packages Conda. Le fichier d'installation correspondant est téléchargeable sur Anaconda.org. Il convient ensuite de suivre la procédure, puis de la finaliser avec cette ligne de code : conda install -c pytorch pytorch.
L’installation de PyTorch est également réalisable depuis l’environnement pip. Selon le système, celui-ci peut demander d’entrer la ligne de code pip install pytorch.
Pourquoi PyTorch est-il utilisé ?
PyTorch se veut d'abord simple à prendre en main. Ce qui le rend à la fois facile d'accès et productif. Ensuite, il s'articule autour d'une architecture dynamique. Résultat : ses réseaux de neurones sont évolutifs au fur et à mesure de leur phase d'apprentissage. PyTorch permet d'ajouter de nouveaux nœuds, modifier les connexions entre eux, y compris d'une couche à l'autre. En aval, le traitement du graph du modèle étant directement adossé au moteur d'exécution de PyTorch, le framework peut aisément être utilisé avec divers environnements de débogage tiers comme PyCharm ou ipdb.
Enfin, l'infrastructure de Facebook prend en charge la data parallelism déclaratif. Une technique qui permet de découper les traitements en multiples mini-batchs afin de paralléliser l'exécution des phase d'apprentissage sur des clusters de serveurs GPU standardisés.
PyTorch vs TensorFlow : quelle différence ?
PyTorch utilise un réseau de neurones dynamique tandis que TensorFlow s'adosse à une architecture de graph statique. C'est là l'une des principales différences entre les deux librairies de deep learning. Résultat : il est beaucoup plus facile avec PyTorch de faire évoluer nativement les structures de réseau de neurones au fur et à mesure de la phase d'apprentissage.
Qu'est-ce que DataLoader dans PyTorch ?
PyTorch est livré avec deux primitives. La première, torch.utils.data.DataLoader, est conçue pour créer des mini-lots de données à partir des datasets d'entrainement. La seconde, torch.utils.data.Dataset, permet d'utiliser des sets de données préchargés.
Plus qu'une bibliothèque, PyTorch est un véritable framework intégrant divers modules. Parmi eux, on compte TorchServe, qui n'est autre qu'un outil pour gérer les déploiements de réseaux de neurones préalablement entrainés, ou encore TorchElastic qui permet de lancer des traitements PyTorch tolérant les pannes sur des clusters Kubernetes.